
重磅!GPT-5.5 Instant全员免费上线:幻觉暴降52%,回复更干脆,还学会看脸色了
【内容摘要】 昨夜,OpenAI毫无预兆地扔下深水炸弹:GPT-5.5 Instant正式接替5.3版本,成为ChatGPT全新的默认模型,且全员免费可用!这次升级堪称“整容级”:不仅幻觉率暴降52...
ChatGPT免费模型大升级!GPT-5.5 Instant上线:幻觉减半、废话砍30%,你的AI助手更懂你了
摘要:5月6日,OpenAI悄然上线了全新的默认模型GPT-5.5 Instant,免费用户即刻可用。本次升级直击大模型两大痛点:在医疗、法律等高风险领域的“幻觉”率暴降52.5%,同时大幅优化了输出...

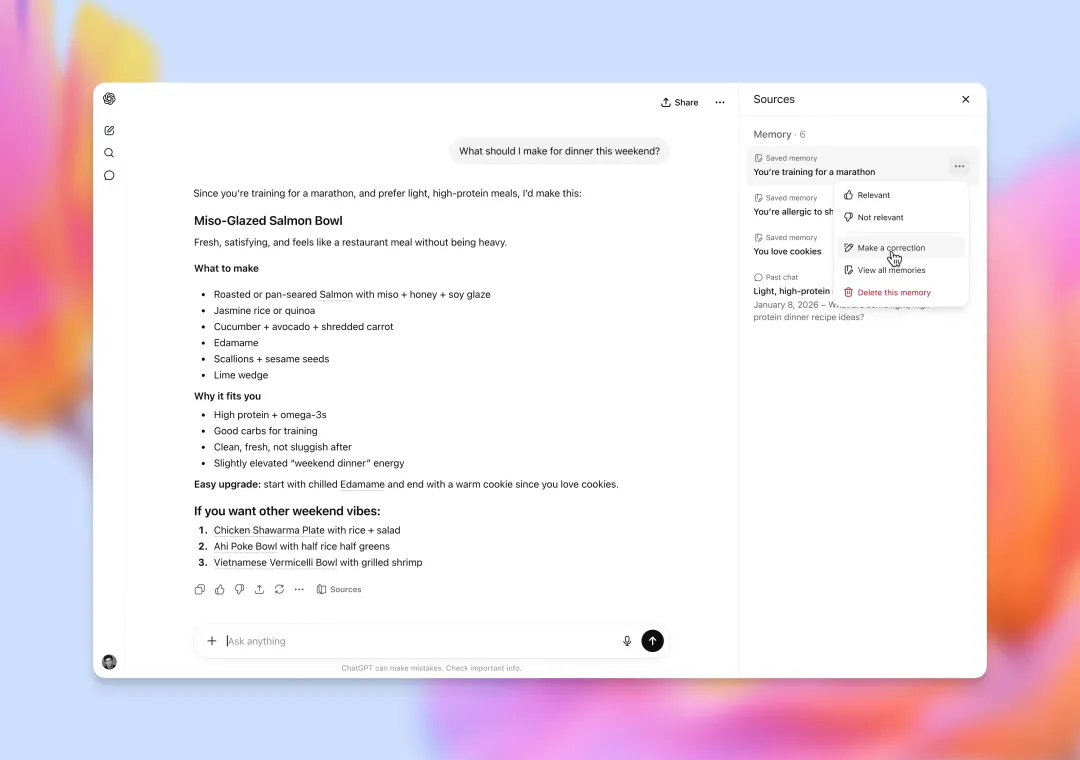
告别AI幻觉与废话!ChatGPT默认模型升至GPT-5.5 Instant,新增记忆来源可视功能
摘要:OpenAI于5月6日正式将ChatGPT的默认模型切换为GPT-5.5 Instant。本次升级直击用户痛点,不仅将医疗、法律等高风险领域的幻觉率暴砍52.5%,还治好了AI的“啰嗦病”,回复...

告别废话,更懂你!GPT-5.5 Instant今日默认上线,奥特曼借AI派对喊话马斯克
摘要: 今天,OpenAI正式将GPT-5.5 Instant推向全网,取代前代成为ChatGPT默认模型。新版本主打“更准、更简、更懂你”,在医疗法律等高危领域的幻觉率暴降52.5%,理科成绩狂飙...

AI桌面端三国杀:Codex、Claude、Gemini 深度横评,谁才是2026最强生产力神器?
摘要:2026年,AI的主战场已从程序员的命令行(CLI)转向大众用户的桌面端。OpenAI的Codex、Anthropic的Claude与Google的Gemini三足鼎立,各有绝活:Gemini胜...

OpenAI Codex席位费限时归零!狂送$500额度硬刚Claude,AI编程迎来普惠时刻?
摘要: OpenAI近期对AI编程工具Codex放出狠招:面向ChatGPT Business和Enterprise用户推出限时优惠政策,不仅Codex专属席位费直接归零,新增席位还能领取最高500美...

ChatGPT防封号教程:一键备份ChatGPT聊天记录与数据导出
摘要:随着GPT-6发布在即,OpenAI风控政策可能收紧,GPT封号风险增加。本文由大国Ai导航(daguoai.com)原创,手把手教你如何导出ChatGPT数据与备份聊天记录,并分享使用Code...
OpenAI Codex 上线桌面宠物:写代码养电子宠物,一键 /pet 唤醒你的 AI 伙伴
摘要: 5 月 1 日,OpenAI 编程工具 Codex 正式上线"Pets"桌面宠物功能——输入 /pet 即可在屏幕角落召唤一只像素风小伙伴。8 只内置宠物各有性格与台词,还支持通过 hatch...

马斯克Grok 4.3低调上线:跑分不及GPT-5.5,性价比与人性化体验却成杀手锏
摘要: 马斯克旗下xAI悄然发布Grok 4.3,没有宏大的AGI叙事,只有务实的升级。新模型在代理任务和语气理解上进步明显,API价格大幅下调,速度提升,成为高性价比的工作助手。但在硬核推理和幻觉控...

独立开发起步:10分钟拿下Apple个人开发者账号(附避坑指南)
摘要: 踏上独立开发或一人公司之路,第一道关卡往往不是写出多牛的代码,而是拿到上架的“许可证”。本文手把手带你实操Apple个人开发者账号的注册流程,从Apple ID双重认证设置,到通过Develo...