
手机“召唤”桌面AI!阿里QoderWork正式打通钉钉、微信、飞书
摘要:2026年3月27日,阿里云宣布其桌面智能体应用QoderWork全面打通钉钉、微信和飞书三大主流即时通讯工具。这意味着,用户现在只需在手机上通过熟悉的聊天软件发条消息,就能远程“召唤”并指挥自...
DeepSeek深夜升级引宕机:V4模型呼之欲出,用户却抱怨“变冷淡了”
2026年3月底,中国AI明星公司深度求索(DeepSeek)再次以一场长达11小时的全面宕机,将自己送上了热搜。这场故障让无数依赖它写论文、敲代码、甚至进行角色扮演聊天的用户陷入崩溃。然而,混乱背后...
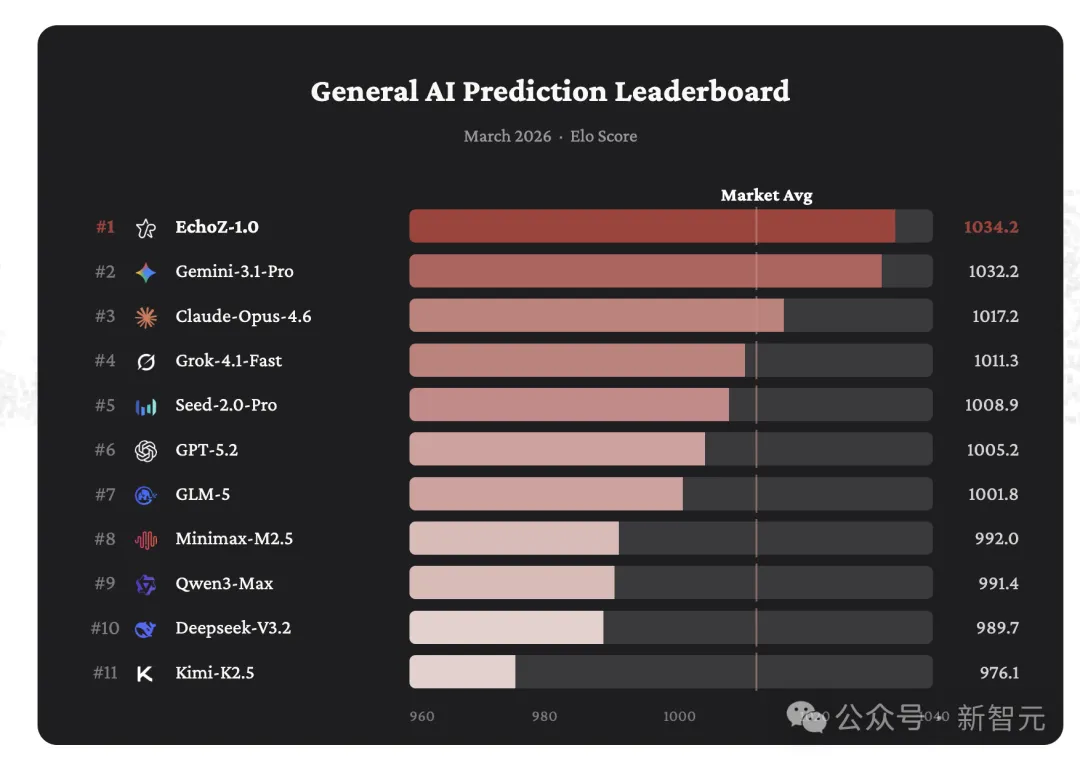
大国AI导航:精准预见未来的新利器——Echo预测系统上线
一个动态评测、持续训练、结果可验证的AI预测系统,正在改变我们获取未来信息的传统方式,为决策者提供超越人类直觉的概率参考。 01 核心摘要:可验证的AI预测时代来临 在信息过载的时代,从纷繁噪音中辨别...

Claude Code Auto Mode正式发布:AI全权接管权限审核,兼顾高自由度与零误操
介绍:近日,Anthropic为其终端AI编程工具Claude Code推出了全新的“全自动模式”(Auto Mode)。该模式通过一个独立的AI分类器,在执行任何操作前进行智能化的语义安全审查,自动...

Claude再放大招!AI数字员工正式接管你的电脑桌面
摘要:2026年3月,人工智能公司Anthropic为其旗舰助手Claude推出了名为“Computer Use”(电脑使用)的革命性功能。这标志着AI从“对话工具”正式进化为能直接操作用户电脑的“数...

Claude Code 命令速查表:开发者必备的AI编程工具箱
Claude Code 命令速查表:开发者必备的AI编程工具箱 Claude Code 是 Anthropic 公司推出的 AI 编程助手命令行工具,它将强大的大语言模型能力深度集成到开发工作流中。不...
GitHub 11万星必装插件Superpowers:让你AI编程助手的输出质量发生质变
一套由14个强制技能组成的AI工作流系统,将你的编程助手从“随意发挥的实习生”变成“遵循最佳实践的专家团队”。 GitHub 上 Star 数突破 11 万、Anthropic 官方插件市场安装量超 ...

Claude Cowork推出Dispatch功能:实现手机遥控、电脑执行的“异地办公”新体验
摘要: Anthropic公司为其AI协作平台Claude Cowork推出了一项名为“Dispatch”(中文可译为“派遣”或“调度”)的新功能。该功能目前以研究预览形式向部分用户开放,其核心理念是...
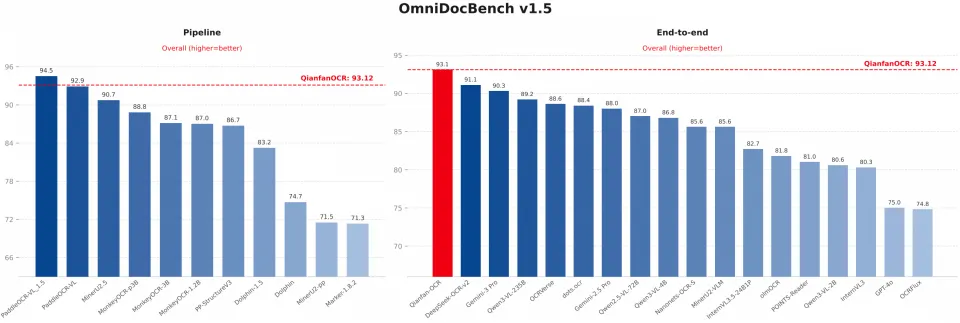
百度千帆发布“王炸”模型Qianfan-OCR:一个模型看懂所有文档,多项评测全球第一
摘要:2026年3月19日,百度智能云千帆大模型平台正式推出革命性的端到端文档智能模型——Qianfan-OCR。这款模型彻底抛弃了传统OCR“检测、识别、理解”的多段式流水线,采用统一的4B参数视觉...
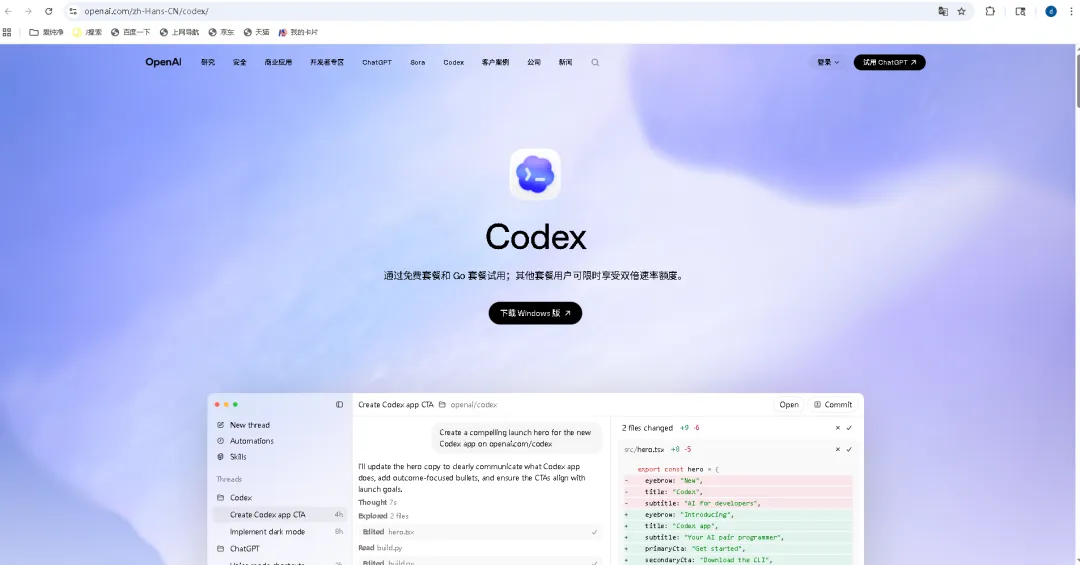
Codex Windows 安装与使用教程:你的AI编程搭档已就位
2026年,OpenAI将其备受瞩目的智能体编程应用Codex正式带到了Windows平台。这款被誉为“AI编程搭档”的工具,专为真实的Windows开发环境构建,集成了最新的GPT-5.3-Code...