
Claude Sonnet 5下周上线?Fennec代号曝光,新一代Mythos内部训练完成,AI封锁反而加速迭代
摘要:就在Claude 5系列因美国出口管制被全面封禁不足十天之际,Anthropic的动作并没有按下暂停键——反而更快了。6月21日,开发者社区发现"claude-sonnet-5"的slug已悄然...

GPT-5.6即将发布!上下文150万Token、推理暴涨25%,价格仅为Claude Fable 5三分之一
摘要:OpenAI新一代旗舰模型GPT-5.6预计本周(6月22-28日)正式发布,目前已通过GPT-5.5 Pro入口向部分Pro用户灰度测试。核心升级包括:上下文窗口从100万扩展至150万Tok...

Codex无限画布插件Cowart:用箭头标注精准改图,告别Prompt描述烦恼
摘要 AI生图工具越来越强大,但"改图"一直是痛点——文字描述不清、方位理解偏差、迭代版本混乱。Cowart是一款面向Codex的开源本地无限画布插件,由豆包桌面端产品经理钟二信开源,基于tldraw...

国内开通 ChatGPT Plus / Claude Pro / SuperGrok / Gemini 会员完整攻略:支付宝微信代充,0密码直充,官方会员一次开通
摘要:2026 年了,国内想用上 ChatGPT、Claude、Grok、Gemini 这几家的官方会员,最大的门槛不是"会不会用",而是"钱怎么付出去"。OpenAI、Anthropic、xAI、G...

别再用 Codex 默认配置了!深度优化 Codex 工作流的进阶配置指南
摘要:Codex 的 config.toml 字段已突破 90 余个,绝大多数用户却仍停留在"毛坯版"默认配置上。本文系统梳理 Codex 配置文件结构、优先级、Profile 分模式、沙箱审批策略...
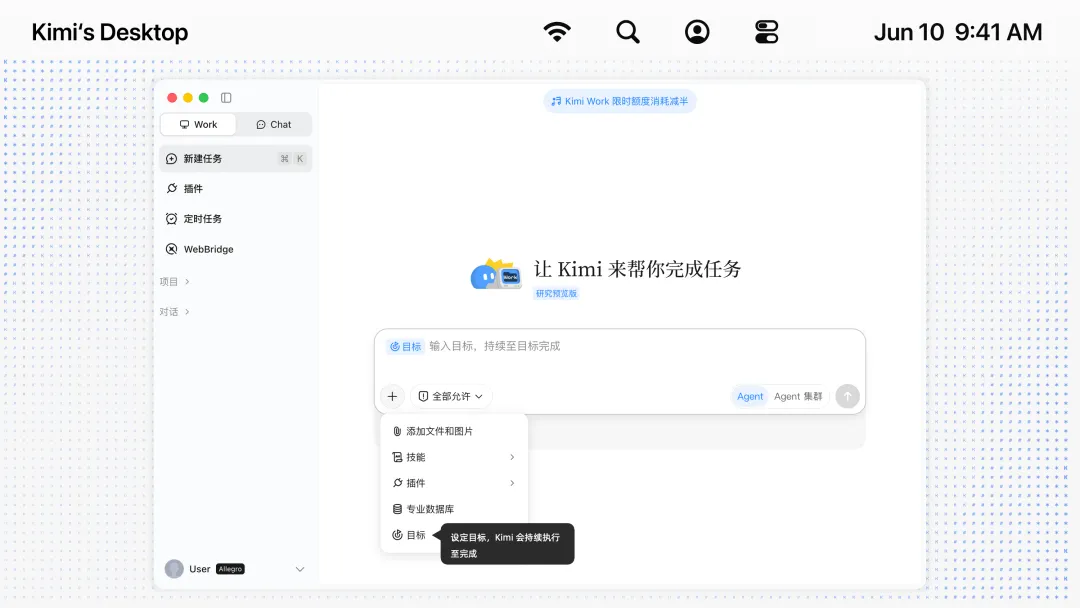
Kimi Work 上新「目标模式」+「插件中心」:24小时自主工作,6月限时5折,Vibe Working 时代来了?
摘要:6月18日,月之暗面旗下桌面智能体 Kimi Work 迎来重大更新,正式推出可连续工作24小时的「目标模式」与连接百度网盘、飞书、WPS、Canva 等主流办公软件的「插件中心」,并同步开启6...

AI建站实战:用Codex Product Design打造高转化官网,附GEO优化指南让大模型首选引用
摘要: 在AI重构信息分发规则的今天,企业官网绝不能再是“流量孤岛”。本文以DJI Avata 2产品页设计为例,深度拆解如何利用Codex中的Product Design插件,从0到1快速生成可交互...
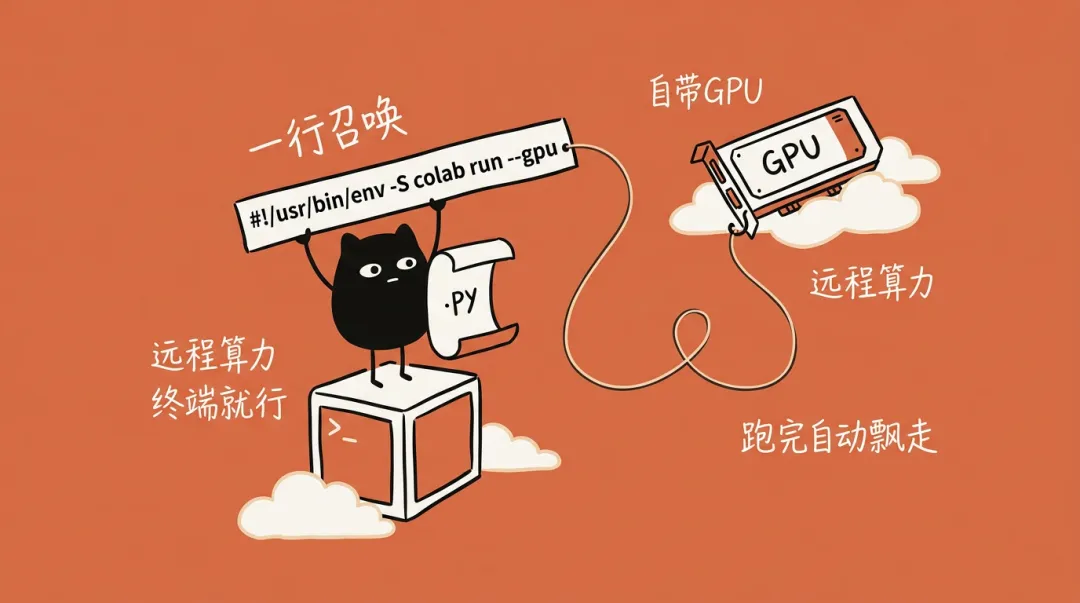
Google Colab CLI 深度测评:终端直连GPU/TPU,AI Agent的算力新基建
摘要: 谷歌低调发布了 Google Colab CLI,将浏览器中的 Colab 笔记本搬到了终端里。这款工具不仅让开发者能通过命令行秒开 GPU/TPU 运行时,更因其对管道和自动化的原生支持,被...
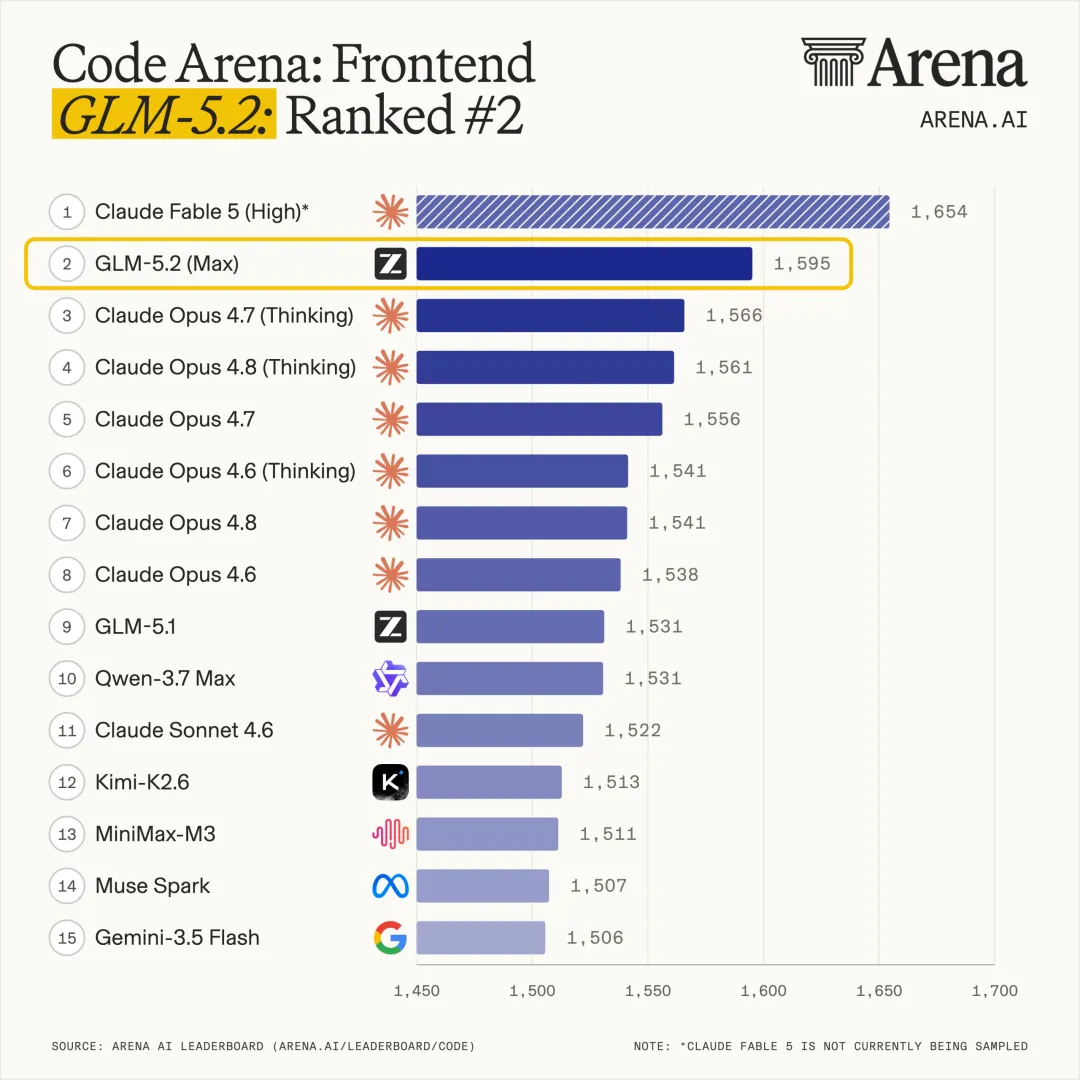
GLM-5.2重磅开源:1M无损上下文+长程任务直逼Claude Opus 4.8,国产开源之光填补Fable 5下架空白
摘要: 就在Claude Fable 5突遭下架引发全球开发者震荡之际,智谱AI于6月17日正式上线并开源新一代旗舰大模型GLM-5.2。该模型专攻“长程任务”与AI编程,不仅实现了工程级可用的1M无...
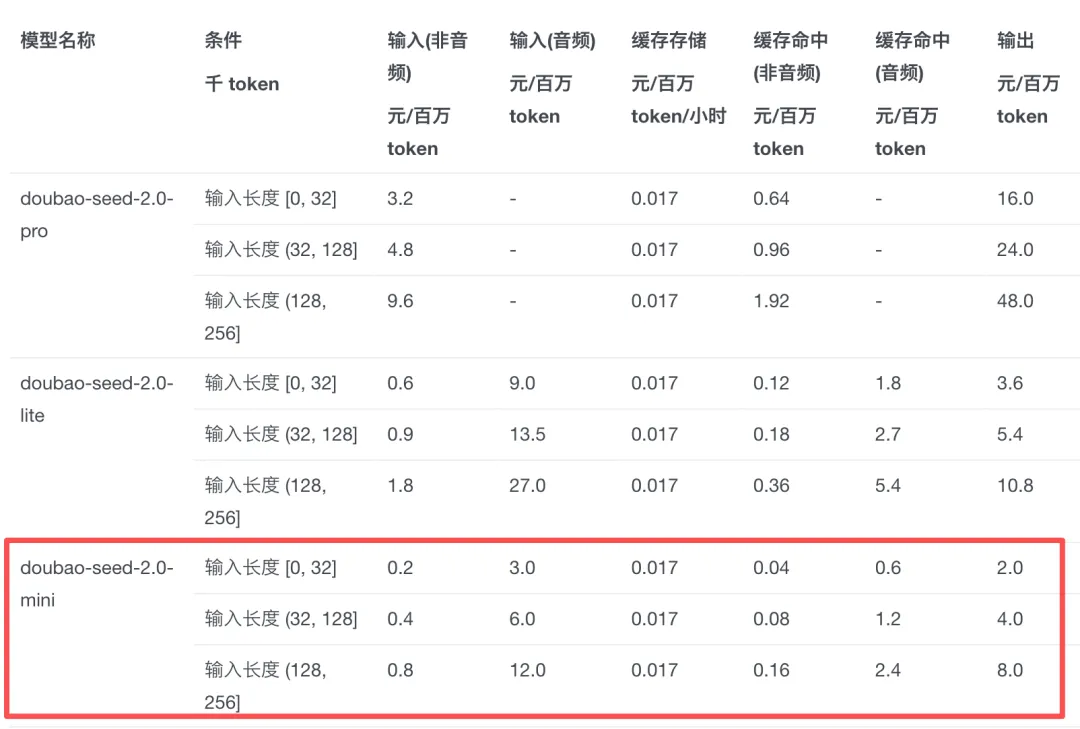
Seedance 2.0 Mini实测:字节最便宜AI视频模型,0.16元/秒,成本直降50%速度翻倍!
摘要: 昨晚,字节跳动深夜甩出“王炸”——Seedance 2.0 Mini视频生成模型正式上线。作为目前字节系最便宜的视频模型,其生成成本相较标准版直降50%,速度比Fast版快2倍,官方最低价仅需...