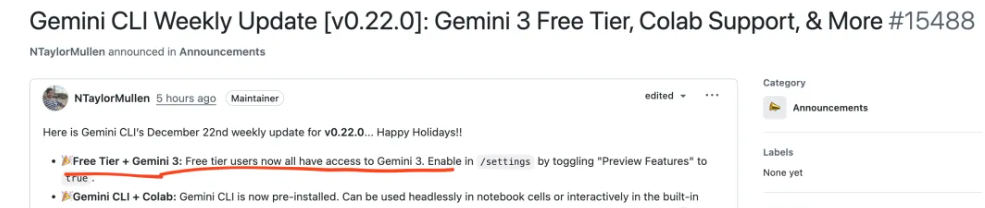
一、技术可行性分析
Stable Diffusion作为开源图像生成模型,其核心机制是通过文本提示词(Prompt)和反向提示词(Negative Prompt)引导图像生成。从技术实现层面看,模型本身不包含内容过滤机制,其生成能力完全取决于训练数据、提示词设计及模型微调方式。
1. 基础生成能力
- 原始模型限制:Stable Diffusion 2.0版本曾移除NSFW(Not Safe For Work)相关训练数据,导致直接生成R18内容难度增加。但通过以下方式仍可突破限制:
- 使用1.x版本模型:早期版本未强制过滤敏感内容,配合特定提示词可生成相关图像。
- 自定义训练数据:通过DreamBooth或LoRA技术,用私有R18数据集微调模型,使其对特定视觉特征敏感。
2. 提示词工程技巧
- 正向提示词:需使用高度具象化的描述,例如:
“nude woman with detailed anatomy, realistic skin texture, 8k resolution”
-
反向提示词:需排除干扰元素,例如:
“clothes, censorship, blurry, low quality”
-
参数优化:
- 采样步数:25-30步(平衡细节与生成速度)
- 分辨率:768×1024(纵向构图更易突出人体)
- 随机种子:固定种子可复现特定画面
二、实际操作流程(技术演示,不鼓励滥用)
1. 环境准备
- 硬件要求:NVIDIA RTX 3060以上显卡(显存≥6GB)
- 软件配置:
- Stable Diffusion WebUI(推荐v1.6.0版本)
- 预训练模型:
stable-diffusion-v1-4-full-fp16.ckpt - 扩展插件:
ControlNet(用于姿态控制)
2. 关键操作步骤
- 启动WebUI:
- 在启动命令中添加
--no-half参数禁用半精度计算,避免数值溢出导致生成失败。
- 在启动命令中添加
- 提示词输入:
- 示例配置
Prompt: “nude art model, standing pose, detailed muscles, studio lighting, 8k resolution”
Negative Prompt: “clothes, blurry, watermark, lowres”
- 高级参数调整:
-
- 启用
Hires.fix进行二次超分(放大2倍) - 使用
Euler a采样器(适合人体结构生成) - CFG Scale值设为7-9(平衡提示词遵循度与创造力)
- 启用
- ControlNet辅助:
- 上传人体姿态线稿图,通过
OpenPose模型锁定关键点,确保生成图像符合预期动作。
- 上传人体姿态线稿图,通过
三、伦理与法律风险警示
1. 技术滥用后果
- 法律层面:
- 中国《网络安全法》明确禁止制作、传播淫秽物品,违法者可能面临刑事处罚。
- 欧盟《AI法案》将生成R18内容列为高风险应用,需通过合规性审查。
- 技术层面:
- 模型开发者可通过哈希值追踪非法生成内容
- 社区平台(如Civitai)已禁止分享NSFW模型
2. 替代方案建议
- 艺术创作方向:
- 使用
anime或semi-realistic风格规避伦理争议 - 聚焦人体解剖学研究(需声明学术用途)
- 使用
- 技术探索边界:
- 通过
inpainting功能局部修改衣物细节 - 利用
Depth2Img模型生成抽象化人体轮廓
- 通过
四、行业治理动态
- 模型升级:
- Stable Diffusion 3.0引入NSFW检测模块,拒绝处理敏感提示词
- 最新
SDXL模型采用双编码器架构,强化内容过滤能力
- 社区自治:
- Hugging Face平台要求NSFW模型必须标注
mature标签 - 主流训练数据集(如LAION-5B)已删除98%的成人内容
- Hugging Face平台要求NSFW模型必须标注
五、技术伦理反思
AI图像生成技术应服务于人类文明进步,而非成为违法工具。开发者需建立:
- 内容生成日志:记录所有提示词与输出结果
- 用户实名认证:绑定生成行为与真实身份
- 动态水印系统:自动标记AI生成内容
结语:本文仅从技术角度解析Stable Diffusion的图像生成机制,坚决反对任何形式的违法应用。建议读者将技术能力用于艺术创作、医学研究等正向领域,共同维护健康的技术生态。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...