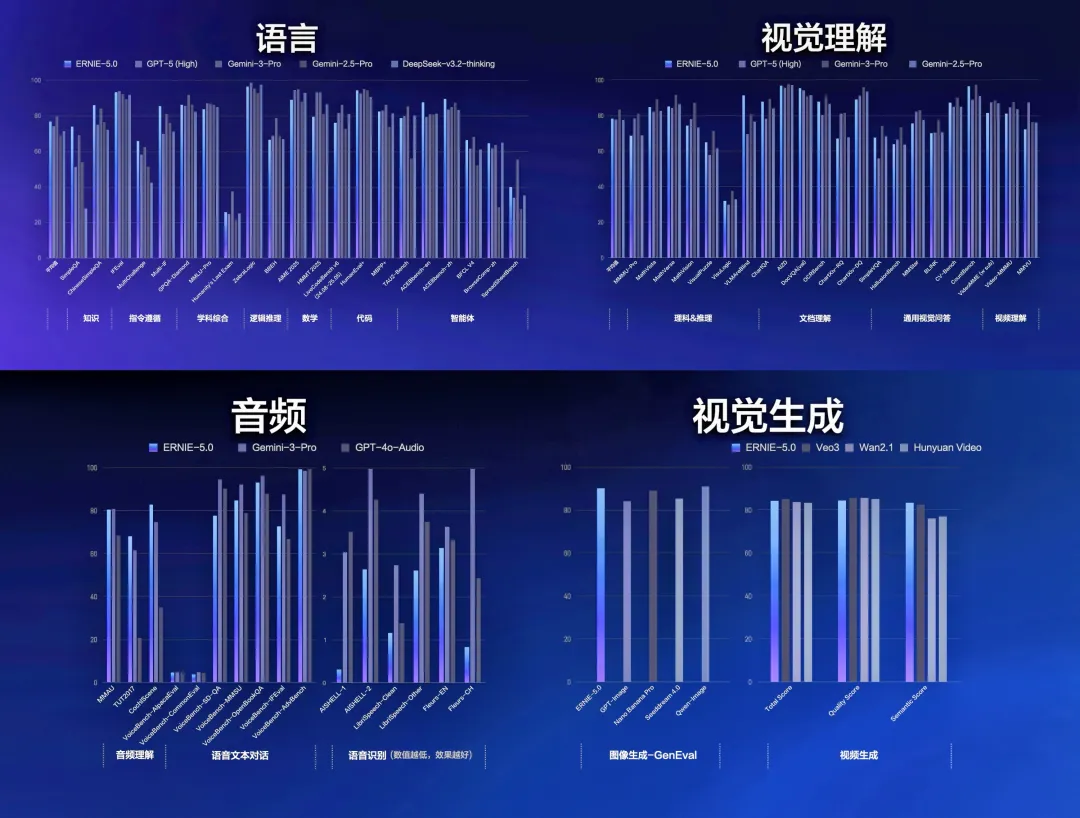
2025年10月发布的PaddleOCR-VL模型,以0.9B参数量在多项OCR基准测试中超越GPT-4o等大模型,登顶HuggingFace Trending全球榜首。
近日,百度飞桨推出的PaddleOCR-VL模型为本地OCR部署带来了全新突破。这款仅需0.9B参数的轻量级模型,在消费级显卡上即可高效运行,支持本地图片和PDF文档的精准解析,为开发者提供了更便捷的OCR解决方案。
一、PaddleOCR-VL:小而强的文档解析模型
PaddleOCR-VL作为文心4.5的衍生模型,采用创新性的两阶段架构设计。第一阶段由PP-DocLayoutV2模型负责文档版面分析,定位语义区域并预测阅读顺序;第二阶段则由PaddleOCR-VL-0.9B进行细粒度识别,完成文本、表格、公式、图表等多类内容的结构化输出。

PaddleOCR
这种模块解耦的设计让模型在面对复杂版面任务时表现更加稳定高效,有效避免了多模态模型常见的幻觉与错位问题。
在权威榜单OmniBenchDoc V1.5中,PaddleOCR-VL以92.6分荣获综合性能全球第一,四大核心能力全线SOTA,超越GPT-4o等模型,刷新了OCR VL模型性能纪录。该模型支持109种语言,能够精准识别文本、手写汉字、表格、公式、图表等复杂元素。
二、消费级显卡友好型部署要求
与需要专业级硬件的大模型不同,PaddleOCR-VL对消费级显卡提供了良好支持。根据实测数据,PaddleOCR-VL-0.9B模型(模型文件约3.8GB)的硬件要求如下:
- 最低配置:6GB显存(勉强够用,单张图)
- 推荐配置:8GB+显存(运行舒适)
- 理想配置:12GB+显存(可批处理多张图)
对于GPU算力要求,官方给出了明确说明:使用原生PaddlePaddle方式需要GPU算力≥8.5(RTX 3090/4090、A100等),最为稳定;使用vLLM方式需要GPU算力≥8(RTX 3060及以上),速度最快但稳定性稍逊。
实际测试中,单张RTX 4090运行PaddleOCR-VL时,显存占用仅1.89GB,剩余空间可留给KV缓存,表现出优异的资源效率。
三、本地部署实战:从环境配置到API服务
1. 环境准备与模型下载
首先安装必要依赖并下载模型文件:
pip install modelscope
modelscope download --model PaddlePaddle/PaddleOCR-VL --local_dir ./PaddleOCR
确保系统环境为Ubuntu 22.04,CUDA版本12.4或12.8均可兼容。
2. vLLM Docker部署
使用Docker容器化部署是最简便的方式:
docker run -d --rm --runtime=nvidia --name paddle-ocr --ipc=host --gpus '"device=1"' -p 8000:8000 -v /data/llm-models:/models vllm/vllm-openai:v0.11.2 --model /models/PaddleOCR --max-num-batched-tokens 16384 --port 8000 --no-enable-prefix-caching --mm-processor-cache-gb 0 --trust_remote_code
此命令会启动一个OCR推理服务,监听8000端口。
3. API服务封装与调用
部署完成后,可通过简单的API调用实现文档解析功能。支持的文件格式包括PDF(.pdf)和图像文件(.png, .jpg, .jpeg)。调用示例:
# 处理PDF文件
curl -X POST " http://localhost:8002/models/v1/models/PaddleOCR/inference " \
-F "file=@/path/to/your/report.pdf"
# 处理图像文件
curl -X POST " http://localhost:8002/models/v1/models/PaddleOCR/inference " \
-F "file=@/path/to/your/receipt.png"
# 使用自定义提示处理文件
curl -X POST " http://localhost:8002/models/v1/models/PaddleOCR/inference " \
-F "file=@/path/to/your/document.pdf" \
-F "prompt=将此文档中的所有表格提取为markdown格式。"
实测表明,该配置下PaddleOCR-VL的推理速度可达1420.7 tokens/s,完全满足实时处理需求。
四、PaddleOCR的技术演进与产业应用
PaddleOCR项目自推出以来,一直是OCR领域的热门开源项目,累计Star数量超过20000+,频频登上GitHub Trending和Paperswithcode日榜月榜第一。
最新版本的PP-OCRv3针对PP-OCRv2的检测模块和识别模块进行了9个方面的升级。其中,识别模块不再采用CRNN,而是更新为IJCAI 2022最新收录的文本识别算法SVTR,并进行了产业适配。
在产业落地方面,PaddleOCR提供了全面的工具集,打通了22种训练部署软硬件环境与方式,包括3种训练方式、6种训练环境、3种模型压缩策略和10种推理部署方式,覆盖企业90%的训练部署环境需求。
五、适用场景与优势总结
PaddleOCR-VL本地部署方案特别适用于:
- 数据敏感场景:文档处理不需上传至云端,保障数据隐私
- 高频使用环境:本地部署避免API调用次数限制和网络延迟
- 成本控制需求:消费级显卡即可运行,降低硬件门槛
- 复杂文档解析:支持表格、公式等非文本元素的精准识别
与传统OCR解决方案相比,PaddleOCR-VL的主要优势在于其优异的精度-效率平衡、强大的复杂文档处理能力以及灵活的部署选项。
随着多模态AI应用的普及,本地化部署的OCR工具将成为文档数字化处理的重要基石。PaddleOCR-VL的推出,为企业和开发者提供了更高效、更经济的解决方案,有望推动OCR技术在更多场景下的落地应用。
文章来源:综合自大国Ai导航、澎湃新闻、光明网等媒体报道,以及PaddleOCR官方技术文档。
相关资源:
- PaddleOCR官网: https://www.paddlepaddle.org.cn
- GitHub仓库: https://github.com/PaddlePaddle/PaddleOCR
- HuggingFace模型页: https://huggingface.co/PaddlePaddle/PaddleOCR-VL
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...