
摘要: 2025年12月4日,快手旗下可灵AI正式推出视频生成2.6模型,其核心创新在于提供了里程碑式的“音画同出”能力。该模型彻底改变了传统AI视频“先无声画面、后人工配音”的流程,能够在单次生成中直接输出包含自然语言对白、动作音效及环境氛围音的完整视频,实现了声音与画面的原生同步。这标志着国内AI视频生成技术,在追赶国际领先水平(如谷歌Veo 3)的竞争中,迈出了关键一步。
技术突破:从“默片”到“有声电影”的质变
长期以来,AI生成的视频内容多为缺乏同步音效的“默片”,需要通过人工后期添加,严重制约了创作效率。可灵Video 2.6模型的发布,正是对这一行业痛点的直接回应。与以往通过独立音效模型(如Kling-Foley)后期匹配声音的方式不同,2.6版本实现了音视频在单次模型推理过程中的一体化生成。
这意味着,用户输入一段文本描述,模型不仅能生成画面,还能同时生成与画面内容在语义、时序上完全匹配的声音,包括人物对话、环境音效和背景音乐。例如,在生成“婴儿在活泼地笑”的视频时,模型能同步还原婴儿的笑声甚至吸气声,并与画面中脸颊的起伏动作精准匹配。这种深度语义对齐,解决了传统AI视频中常见的“嘴型不对、情绪不连贯”等问题,使生成结果更接近真人拍摄的视听体验。
功能详解:两大核心创作模式
可灵Video 2.6模型主要升级了以下两大功能,重构了AI视频创作的工作流:
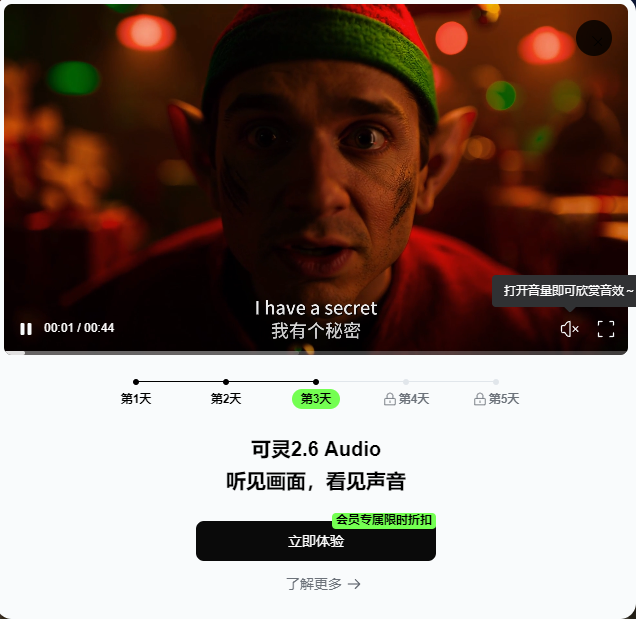
- 文生音画:用户仅需输入一句文本描述,即可直接获得一段带声音的完整视频。例如,描述“一个年轻女性在温馨客厅轻声说‘I have a secret…’”,模型将同步生成对应的画面、人物语音及室内环境音。
- 图生音画:用户上传一张人物或场景图片,并配以文字描述,即可让静态图片“动起来”并“开口说话”。这极大简化了产品讲解、访谈短剧等内容的制作流程。
目前,模型生成的视频最长支持10秒,分辨率达1080p,语音支持中文和英文。在动作连贯性、镜头衔接和角色一致性方面,该版本也比前代模型更为稳定。
行业背景:音画同步已成AI视频竞争关键节点
可灵此次升级并非孤立事件,而是全球AI视频生成技术演进趋势下的重要落子。谷歌Veo 3模型因实现原生音画同步而大受欢迎,已表明“音视频的同步输出,已成为生成式AI的下一个关键节点”。在国内市场,除可灵外,字节跳动即梦AI也推出了名为SeedFoley的视频音效智能生成模型。
快手可灵在视频生成领域的布局起步较早,其商业化进程也较为迅速。根据公开报道,可灵AI的年化营收(ARR)在今年3月已突破1亿美元,用户规模超过4500万。此次推出原生音画同出模型,是其巩固技术领先优势、满足专业创作者对高效工作流需求的关键举措。
从“尝鲜玩具”到“生产工具”,AI视频生成正走向规模化应用。有案例显示,专业创作者利用AI工具,仅以数百美元的成本和数周时间,便能制作出过去需要高昂预算的短片。可灵Video 2.6通过简化音频制作环节,将进一步降低视频创作的门槛与技术成本,释放其在广告、影视、短视频、游戏等领域的应用潜力。
提示词创作指南:如何用好“音画同出”
为了充分发挥新模型的潜力,获得更精准的生成效果,创作者在编写提示词(Prompt)时需要更有策略。核心原则是将视觉描述与音频描述进行结构化结合。
一个有效的提示词公式可参考:场景描述 + 主体描述 + 运动描述 + 音频描述(对话/音效/音乐)+ 风格/情感/镜头语言。
对于包含多角色对话的复杂场景,需注意:
- 结构化命名:为每个角色赋予唯一且固定的标签(如[黑衣特工]、[女助手]),避免使用代词。
- 视觉锚定:将角色的台词与其具体动作绑定描述(如“黑衣特工猛地拍桌,愤怒地喊:‘真相在哪?’”)。
- 音频细节:为每个角色添加音色(沙哑、清亮)、情绪(愤怒、恐惧)和语速(快速、缓慢)等标签。
- 时序控制:使用“紧接着”、“随后”等连接词明确对话顺序和节奏。
对于音效与环境声,建议明确声音来源、动作状态并使用专业拟声词,例如:“【物体:木门】猛地【动作:关上】+【拟声词:砰】”。
模型定价与获取
可灵Video 2.6模型提供“音画同出”与“纯视频生成”两种模式。根据官方信息,其消耗的“能量值”依据视频时长和用户身份有所不同:
- 会员价格:生成5秒视频消耗15点能量,10秒视频消耗30点能量。
- 非会员价格:生成5秒视频消耗20点能量,10秒视频消耗40点能量。
该模型已集成在可灵AI平台中,用户可通过其官网或集成该模型的快影App进行体验。
文章来源:本文综合自每日经济新闻《可灵2.6模型上线 提供“音画同出”能力》、央广网《可灵AI全系模型上线“视频音效”功能》、界面新闻《谁在AI ASMR淘金热中赚翻了?》、第一财经《快手可灵是如何在视频生成领域赚到第一个1亿美元的?》等公开报道,由大国AI导航(daguoai.com)整理改写。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...