核心摘要:2026年3月11日,谷歌DeepMind正式发布了业界首个原生多模态嵌入模型——Gemini Embedding 2(模型ID:
gemini-embedding-2-preview)。该模型基于Gemini架构构建,其革命性在于将文本、图像、视频、音频和文档五种模态的数据,直接映射到同一个统一的向量空间中。这意味着开发者可以用一段文字去搜索相关的图片或视频,也可以用一张图片去匹配对应的音频或文档,真正实现了跨模态的语义理解和检索,被誉为“多模态RAG的新基准”。
目前,该模型已通过 Gemini API 和 Google Cloud Vertex AI 平台提供公开预览,开发者可即时接入。
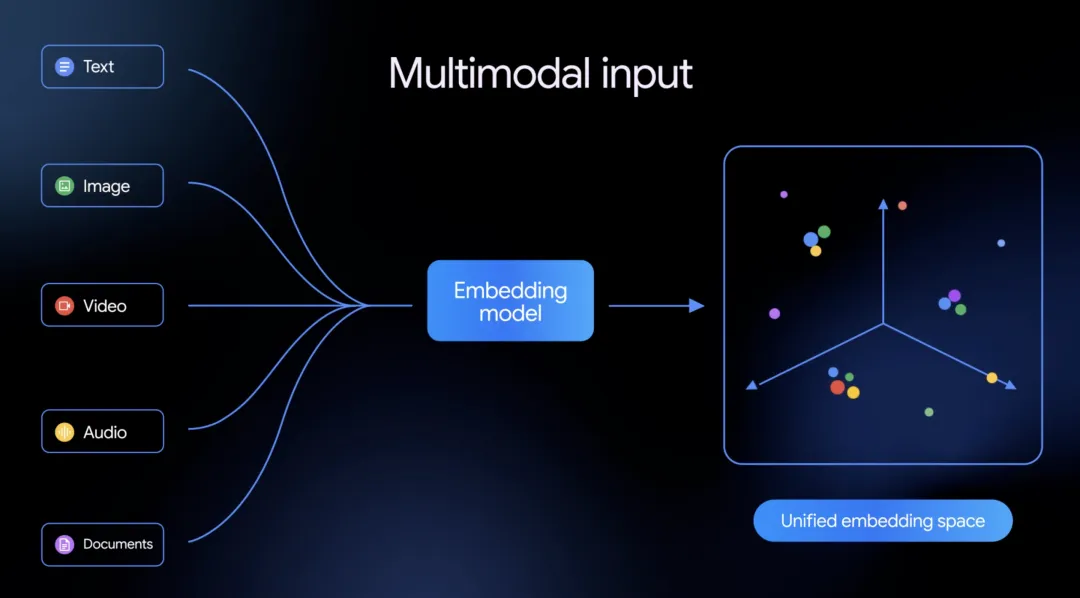
核心突破:告别“拼乐高”,迎来“原生统一”
传统的多模态处理方案如同“拼乐高”,需要组合多个专用模型(如CLIP处理图像、Whisper转录音频),再将生成的向量进行对齐,流程复杂且存在语义损耗。Gemini Embedding 2从底层改变了这一范式:
- 真正的原生多模态:模型并非多个单模态编码器的拼接,而是基于统一的Transformer架构,让五种模态共享同一组参数进行编码,从根本上解决了跨模态语义鸿沟。
- 支持交错输入:可在单次API请求中,同时传入“图像+文本描述”、“视频+音频”等多种模态组合。模型会综合理解其间关系,生成一个融合的语义向量。
- 音频处理无需转录:可直接处理原始音频波形(如MP3、WAV文件),无需先通过语音识别(ASR)转成文字。这保留了语调、情感、背景音等关键非文本信息,对客服质检、法律取证等场景意义重大。
技术详解:三大核心能力支撑
- “套娃”表示学习(MRL):模型采用Matryoshka Representation Learning技术,其输出的高维向量像俄罗斯套娃一样,前缀部分即是有效的低维向量。这带来了极大的灵活性:
- 默认输出:3072维向量。
- 动态压缩:可根据存储和计算成本需求,直接指定输出为1536维或768维,而精度损失极小(从3072维降至768维,在MTEB基准上得分仅下降约0.5)。这能为海量数据存储节省高达75%的成本。
- 全面的模态支持规格:
- 文本:支持高达8192个输入Token的长上下文,覆盖100多种语言。
- 图像:单次请求最多处理6张,支持PNG/JPEG格式。
- 视频:支持最长120秒的MP4/MOV文件。
- 音频:支持原生嵌入,无需转录。
- 文档:可直接嵌入最多6页的PDF文件,包括其中的图文混排内容。
- 任务类型优化:通过指定
task_type参数,可让模型为特定场景优化嵌入质量,例如RETRIEVAL_QUERY(查询)、RETRIEVAL_DOCUMENT(文档)、SEMANTIC_SIMILARITY(语义相似度)等,从而获得更精准的结果。
性能实测:全面领先的硬实力
根据谷歌公布的基准测试结果,Gemini Embedding 2在多项任务中确立了新的性能标杆:
- 文本-文本检索:在衡量多语言语义理解能力的MTEB(Mean Task)基准上,得分69.9,高于前代模型(68.4)及主要竞品。
- 代码语义理解:在MTEB Code基准上得分84.0,相比前代提升8个点,显著增强了对技术文档和代码的检索能力。
- 图文跨模态检索:在TextCaps数据集上,文本到图像检索得分89.6,图像到文本检索得分高达97.4,大幅领先其他模型。
- 产业级效果:早期合作伙伴反馈,在数百万条记录的诉讼取证场景中,该模型显著提升了检索精度和召回率。另一家公司Sparkonomy称,借助其原生多模态能力,延迟降低了70%,跨模态语义相似度得分实现了翻倍提升。
落地场景:从概念到生产力的跨越
这一技术突破将直接赋能多个高价值应用场景:
- 智能知识库与RAG:企业内部的合同、财报PDF、会议录音、产品图片、监控视频等所有资料,可以统一向量化存入一个数据库。员工能用自然语言或一张图片,一次性检索出所有相关的跨模态信息,极大提升法务、金融、研发等领域的效率。
- 下一代电商与内容搜索:用户上传一张“红色碎花连衣裙”照片,并输入“棉质、500元以内”的文字描述,系统能同时在海量商品图、详情页文字、买家秀视频、客服语音评价中进行精准的跨模态语义匹配。
- 媒体资产管理:广告公司、电视台可利用统一向量空间,管理海量的视频片段、音频素材、海报设计图。创意人员可以用“类似苹果1984广告的冷峻科技感”这类抽象描述,直接检索出符合感觉的跨格式素材。
- 交互式Agent:为AI智能体(Agent)提供了“通感”能力,使其能像人类一样,综合理解文字、图像和声音,做出更精准的决策和响应。
开发者如何开始: 模型已提供Python、JavaScript、Go等多种语言的SDK,并官宣支持LangChain、LlamaIndex、Weaviate、Qdrant、Chroma等主流开发框架和向量数据库。需要注意的是,新模型的向量空间与旧版本(如gemini-embedding-001)不兼容,迁移时需要重新索引数据。
文章来源:本文核心信息综合自大国AI导航提供的资讯稿[^用户文档],并参考了谷歌官方API文档及多家科技媒体(如新浪科技、金融界等)于2026年3月11日的同步报道,对模型细节、性能数据及生态信息进行了补全。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...