
一次代码重构,顶尖工程师花了数天,而GPT-5.5在回溯测试中给出了完全相同的解决方案——这不再是简单的代码补全,而是具备了“概念清晰度”的智能伙伴。
2026年4月24日凌晨,ChatGPT正式推出了GPT-5.5,官方将其定位为“一种面向实际工作和智能体的新型智能”。
与此前版本最大的不同在于,GPT-5.5在保持响应速度的同时,实现了智能水平的显著跃升,打破了AI领域“更强就必须更慢”的固有认知。
然而,伴随能力提升的是价格翻倍:API调用费用达到每百万输入token 5美元、输出token 30美元。
01 发布反响:早期测试者的“戒断反应”
OpenAI此次没有让CEO萨姆·奥特曼亲自讲述“初体验被吓到眩晕”的感受,而是让早期测试用户成为“嘴替”。
其中一位英伟达工程师的反馈尤为引人注目:“失去对GPT-5.5的访问权限,感觉就像我被截肢了一样。”
这种强烈的依赖感源于GPT-5.5与英伟达前所未有的深度合作。双方宣布,GPT-5.5与英伟达GB200、GB300 NVL72系统是联合设计的,从训练到部署实现了硬件与软件的双向优化。
英伟达CEO黄仁勋在内部邮件中兴奋地表示:“点燃那些Blackwell芯片吧!我们需要更多token!”
他将OpenAI的Codex系统推广至英伟达全公司,覆盖工程、产品、法务、市场等上万名员工。一位员工感叹“这真的改变了我的生活”,另一位则说“这东西让我震惊”。
GPT-5.5
02 技术突破:打破“更强就更慢”的铁律
过去每一次模型升级,“更强”和“更慢”几乎是打包出售的。这是Scaling Law的代价:更大的模型、更多的参数意味着更长的思考时间。
GPT-5.5打破了这条铁律。在真实生产环境中,它的逐token延迟与GPT-5.4相当,但完成相同任务所需的token数量却更少。
效率更高,功能更强大——尽管价格也翻倍了。
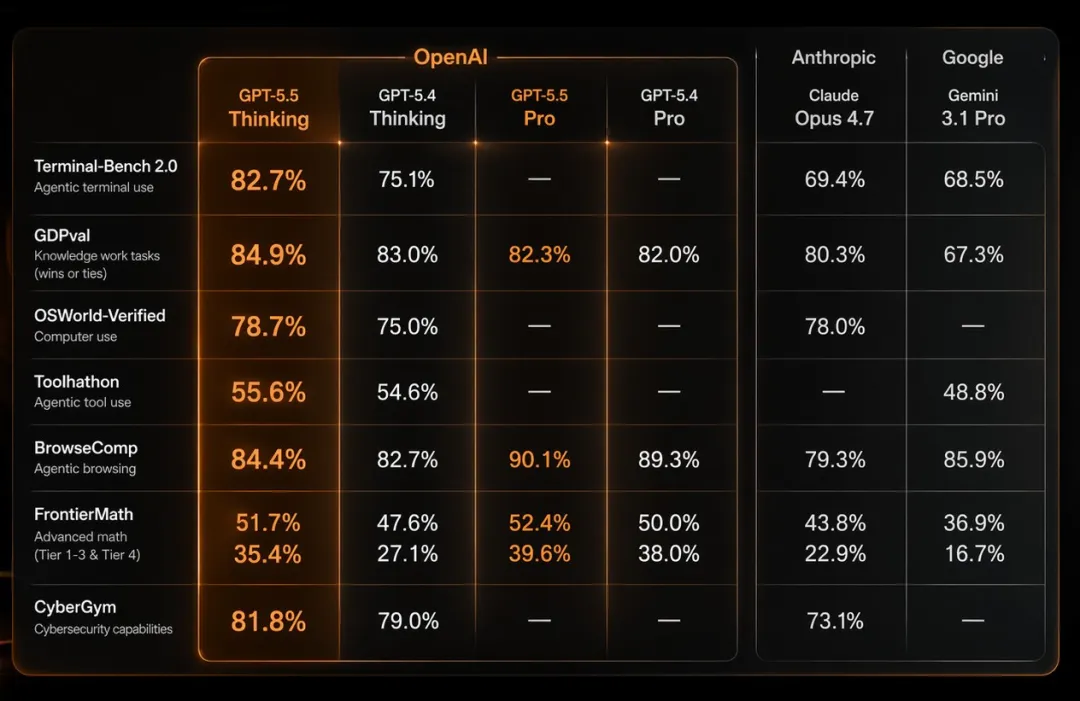
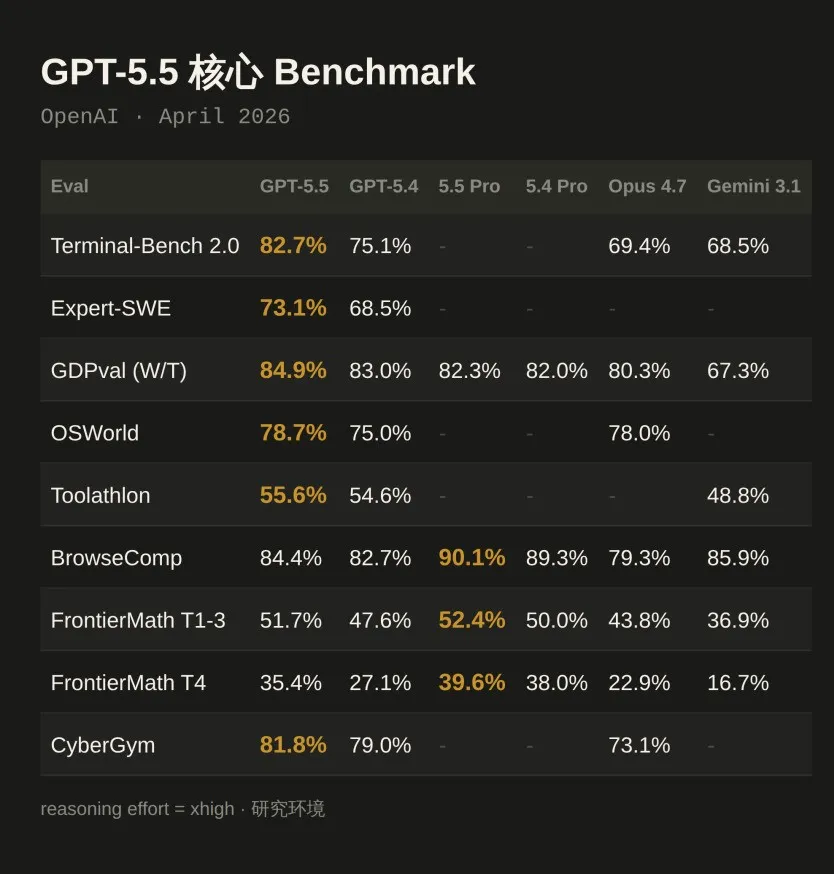
OpenAI公布的数据显示,GPT-5.5在代码、知识工作、科学研究三个核心领域全面领先:
- Terminal-Bench 2.0(复杂命令行工作流测试):82.7%,较GPT-5.4的75.1%提升显著
- GDPval(知识工作任务基准):84.9%,领先Claude Opus 4.7达4.6个百分点
- FrontierMath Tier 4(顶级数学难题):GPT-5.5 Pro达到39.6%,几乎是Claude Opus 4.7(22.9%)的两倍
在综合测试Artificial Analysis Intelligence Index中,GPT-5.5展现出两种优势:获得相同分数时消耗的token更少,或消耗相同token时完成的任务更多。
03 编程革命:从“接话”到“理解问题”
编程是GPT-5.5提升最猛的领域。上一代模型使用时,仍需小心翼翼地拆解任务,一步步监督执行。
GPT-5.5完全不同:你把需求丢过去,它自己拆解、自己执行、自己检查,你只需要看结果。
OpenAI展示了Codex下GPT-5.5生成的3D动作游戏,在网页上直接运行,包括用TypeScript/Three.js实现战斗系统、敌人遭遇、HUD反馈以及AI生成的环境纹理。
初创公司Every的创始人兼CEO丹·希珀做了一个实验:他的应用上线后出现了一个bug,他请来一位顶尖工程师花了几天时间重构部分系统。
随后,他将时钟拨回,将有bug的代码丢给GPT-5.5,看它能否独立做出与那位工程师相同的决策。
GPT-5.4做不到,GPT-5.5做到了。
希珀评价道:“这是我用过的第一个具有真正‘概念清晰度’的编程模型。”这不是简单的接话,而是在理解问题后自己想明白如何解决。
越来越多高级工程师反馈同一现象:GPT-5.5在推理和自主性上明显强于前代,能够提前发现问题,并在无需明确提示的情况下预测测试和审查需求。
04 知识工作:从工具到“研究伙伴”
GPT-5.5在Codex里能做的远不止写程序。生成文档、整理表格、制作PPT——它比上一代更懂你想要什么。
关键的是,它会自己使用工具、自己检查输出正确性。你给出一个模糊的想法,它能帮你补完剩下的。
OpenAI透露,公司内部超过85%的员工每周都在使用Codex工作。
在科研领域,GPT-5.5展现出更惊人的能力。波兰亚当·密茨凯维奇大学的数学助理教授巴托什·纳斯克伦茨基给Codex写了一句话,11分钟后,一个代数几何可视化应用就跑起来了。
杰克逊基因组医学实验室的免疫学教授代里亚·乌努特马兹用GPT-5.5 Pro分析了一份基因表达数据集:62个样本,近28000个基因,最终产出了一份完整的研究报告。
他说:“这本来要花团队几个月的时间。”
05 数学突破:AI解决数十年难题
GPT-5.5在数学领域做了一件里程碑式的大事:它针对拉姆齐数这一组合数学核心问题,找到了一条新的证明路径。
拉姆齐数研究的是:一个网络要大到什么程度,才能保证某种秩序必然出现?这个问题困扰了数学界数十年。
GPT-5.5发现的证明随后被数学界最严格的形式化验证工具之一Lean确认无误。
一个AI在纯数学的核心领域做出了被形式化工具验证的原创贡献——这在一年前还不可想象。
06 更强却不更慢的秘密:AI优化自身基础设施
“更强却更快”是如何实现的?答案不是单一环节的优化,而是OpenAI将整个推理系统推倒重来。
GPT-5.5与英伟达硬件的联合设计确保了在同等延迟下实现智能水平的大幅跃升。
但还有另一个更惊人的故事:GPT-5.5驱动的Codex系统分析了数周的生产流量数据,然后自己写出了一套负载均衡的分区启发式算法。
此前,请求被切分成固定数量的块分发给加速器处理,但固定策略在不同流量模式下并不总是最优。
Codex通过分析真实流量数据,开发出自适应分区算法,能够根据实际流量形态动态调整分块策略,最终使token生成速度提升超过20%。
模型正在优化自己运行的基础设施——AI在让自己跑得更快。
07 国产大模型的对比与启示
在GPT-5.5发布之际,回顾国产大模型的发展颇具意义。根据大模型测评网站Artificial Analysis的数据,在GPT-5发布时,排名前列的已有阿里的通义千问和DeepSeek。
而在开源模型榜中,排名前十的有六个是国产大模型。
国产大模型在应用落地方面展现出独特优势。例如,阿里千问与高德地图的深度融合,实现了从“听清”到“听懂”的跨越。
用户只需说出“找家安静咖啡厅办公”,系统就能推荐符合要求的门店,并标注实时人流量、插座分布和最新评价。
这种AI大模型与位置服务的深度融合,标志着智慧出行迈入新阶段。未来,随着场景理解能力的持续提升,地图或将主动预判用户需求,提供更加个性化、前瞻性的服务。
08 未来展望:AI发展进入加速期
有了GPT-5.5,OpenAI预计模型发布节奏将加快。首席科学家雅库布·帕霍茨基在与记者的电话会议上表示:
“我们看到短期内有相当显著的进步,中期有极其显著的进步。我认为过去几年进展出乎意料地缓慢。”
当模型已经开始优化自己运行的基础设施,这一步到底迈了多远?
GPT-5.5不仅是一次技术升级,更是人机协作范式的转变。它不再是一个简单的问答工具,而是能够理解复杂需求、自主规划任务、甚至优化自身运行环境的智能伙伴。
随着GPT-5.5的推出,AI正在从“会聊天”向“能办事”加速演进,这场变革将深刻改变编程、科研、知识工作乃至数学研究的方式。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...