
摘要: 千呼万唤始出来!DeepSeek V4 今日正式发布 API,带来 V4-Flash 与 V4-Pro 双版本,支持百万上下文、JSON 输出及原生工具调用。其中 Flash 版本输入低至 ¥0.2/百万 token,再次击穿行业底价;Pro 版本专注深度推理,定价仅为海外同类模型的零头。
今天上午,DeepSeek V4 的 API 定价表终于在官网悄然上线。没有冗长的发布会,也没有铺天盖地的预热,但这几张截图已经在开发者群里炸开了锅。
V4 这次没有走单模型的路线,而是直接甩出了两张王牌:V4-Flash 和 V4-Pro。如果你还记得上个月初那场悄无声息的灰度测试,当时网页端把原有的“深度思考”和“联网搜索”换成了“快速模式”和“专家模式”,现在看来,那就是 V4 双模型策略的雏形。
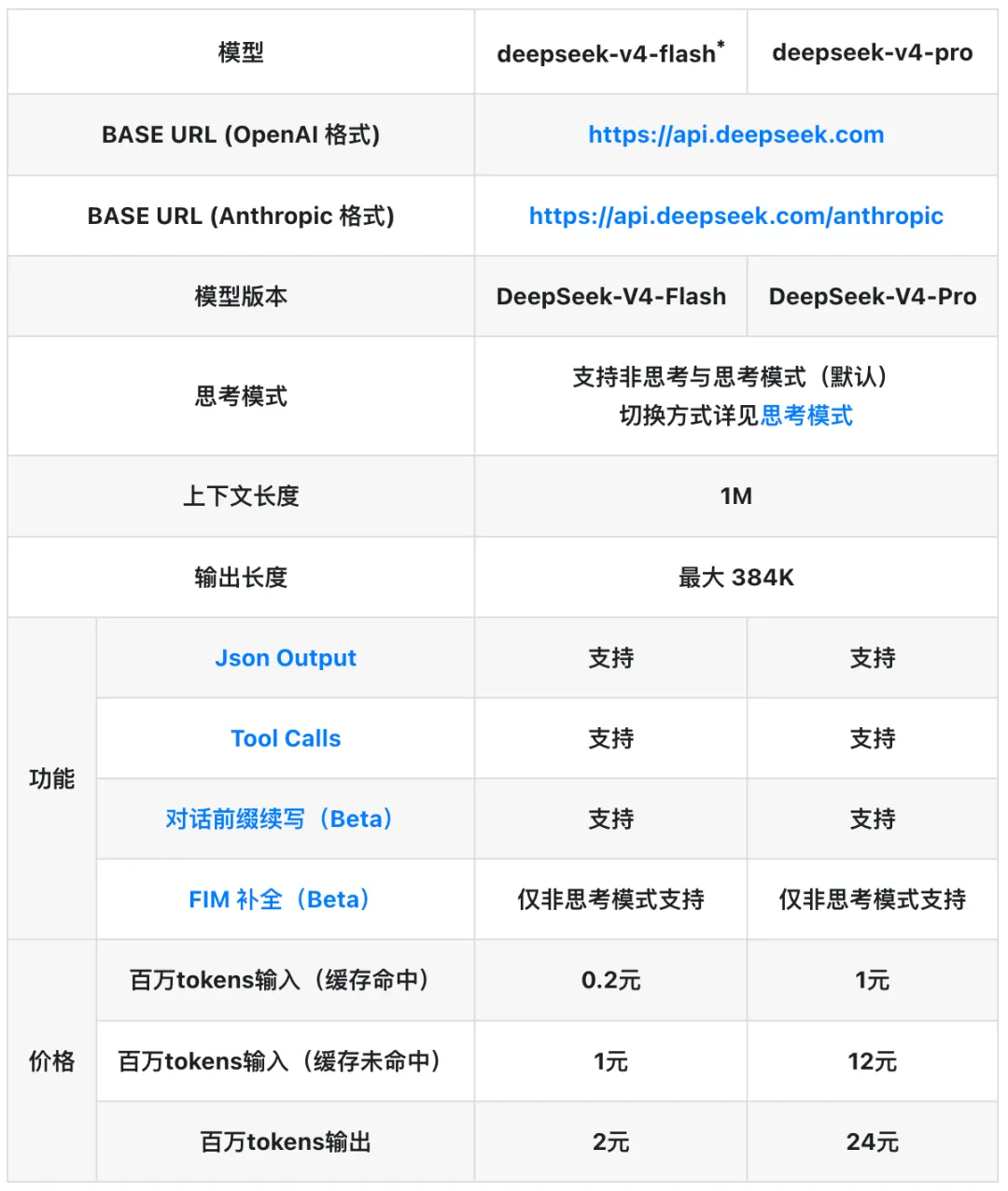
一、双模型定位:极速 Flash vs 深度 Pro
Flash:主打一个“快准狠”,价格低到离谱
V4-Flash 的定价一出,估计不少小团队的 CTO 都要连夜改架构了。每百万 token 输入 ¥0.2,输出 ¥1。这是个什么概念?之前各大媒体和开发者猜测 V4 怎么也得 ¥4/¥16 起步,结果 Flash 直接把价格打到了脚踝斩。对于那些需要高频调用、处理海量并发但又不需要深度烧脑的场景——比如日常客服、批量文本分类、简单代码补全——Flash 简直就是白嫖级的体验。
Pro:专治各种“疑难杂症”,深度推理的终极武器
如果说 Flash 是效率工具,那 V4-Pro 就是攻坚利器。输入 ¥1/百万 token,输出 ¥12/百万 token。这个价格虽然比 Flash 贵,但考虑到 Pro 对应的就是之前的“专家模式”(深度思考推理),它能搞定复杂的数学逻辑、多步代码调试和长链条规划。相比于海外同级别动辄几十上百元的输出价格,V4-Pro 依然是性价比怪兽。
此外,V4 对100 万上下文的支持也给出了明确的计费规则:当你在 100 万上下文下使用时,输出价格翻倍。这种阶梯定价非常务实,毕竟处理 100 万 token 的长文本(相当于一次性塞进整部《三体》三部曲)对显存和算力的消耗是巨大的,得益于全新的 Engram 条件记忆架构,V4 才得以将百万上下文的检索准确率拉到 97%。
二、四大开发者神技全部拉满
除了价格,这次 V4 在功能适配上也终于补齐了之前被诟病的短板,开发体验直接拉满:
- JSON 输出:不用再写各种提示词让模型强行吐 JSON 了,原生支持意味着接口对接稳如老狗,结构化数据提取零幻觉。
- 工具调用:之前 V3 在这方面还是弱项,需要各种 prompt hack,现在原生支持 Tool Calling,Agent 工作流跑起来会更顺滑,不再动不动就卡壳。
- 对话前缀续写:这对于做对话机器人的同学来说是神器,可以精准控制 AI 的回复开头,人设一致性大幅提升。
- FIM 补全:Fill-in-the-Middle,填空式补全,代码补全场景的刚需,Cursor 类工具的底层基石,写代码丝滑度再上一档。
三、背后的底气:万亿 MoE 与国产算力
能定出这个价格,不是赔本赚吆喝,而是技术底座足够硬。V4 延续了 DeepSeek 一贯的万亿参数 MoE 架构,但引入了 Engram 条件记忆、mHC 流形约束超连接以及 DualPath 推理加速等多项底层创新,把推理成本死死压住了。
更关键的是,多方消息证实,V4 是首个完全运行在华为昇腾 950PR 等国产算力芯片上的旗舰模型,彻底告别了对英伟达 CUDA 生态的依赖。这不仅是技术突围,更是成本自主权的宣示——当别人还在为 H20 算力卡脖子发愁时,DeepSeek 已经用纯国产算力跑通了万亿模型的商业化闭环。
V4 这波操作,真的是不给友商留活路。赶紧去调接口吧,别让羊毛跑了!
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...