
摘要:2026年7月1日,谷歌正式将Gemini Omni Flash视频生成与编辑能力开放至Gemini API和Google AI Studio,同时推出号称”迄今为止最快、最经济高效”的图像模型Nano Banana 2 Lite。前者内置Gemini世界知识,支持对话式视频编辑,每秒成本仅0.10美元;后者4秒出图、单张1K图像约0.034美元,两者可串联使用实现”图像→视频”全链路自动化。这标志着谷歌在多模态赛道上打出一套组合拳,直接剑指电商、装修、短视频等垂直场景的商业化落地。
一、Gemini Omni Flash:视频版Nano Banana正式登场
在2026年5月19日的Google I/O大会上首次亮相后,Gemini Omni Flash终于在本周通过Gemini API和Google AI Studio正式向开发者开放。这个被谷歌定位为”万物生成世界模型”的首发版本,把Gemini的多模态推理能力与视频生成、编辑深度结合,被视为谷歌在多模态赛道上的王牌之作。
四项核心能力
根据谷歌官方披露,Gemini Omni Flash具备四项关键能力:
- 对话式视频编辑:用户可以用自然语言修改和精修视频,操作体验类似改飞书文档。模型通过维持”场景状态向量”(scene state vector),每次对话指令修改状态向量后重新渲染,比传统的Inpainting方式稳定得多,不会出现”改了背景却把主角脸糊掉”的尴尬。
- 多模态参考:可组合图像、文本、视频输入,在保持场景控制和一致性的前提下生成视频。支持文本到视频、图像到视频、音频到视频、视频到视频以及混合输入生成等多种模式。
- 现实世界知识:模型能调用Gemini在历史、生物、叙事逻辑等方面的知识来构建视频,无需用户写三页Prompt描述建筑风格。该模型结合了对物理的直觉理解(如重力、流体动力学、动能)与Gemini对历史、科学和文化背景的知识。
- 文字与动作同步:通过简单提示词,将文字和图形直接连接到视频动作。
底层架构与定价
Gemini Omni Flash采用谷歌第四代Mixture of Experts(混合专家)架构,每次生成视频时只激活最相关的10%-15%参数,推理速度提升3-5倍,计算成本降低至1/3。官方标称生成一个10秒720P视频仅需6秒,第三方实测平均耗时5.2秒。
价格方面,每秒视频输出成本0.10美元,与Veo 3.1 Fast持平。在国内API渠道,有服务商给出0.035元/秒的定价,相比标准版Omni的0.105元/秒,成本直接砍至三分之一。
现阶段局限
谷歌也坦诚列出了当前版本的局限:
- 目前只支持10秒视频生成,后续会支持更长
- 暂不支持音频参考上传和场景扩展
- API支持最长3秒的视频作为参考素材,但模型还无法正确处理这类输入
- 场景切换和运镜时的人物一致性仍有局限
二、Nano Banana 2 Lite:4秒出图,1元钱做四张
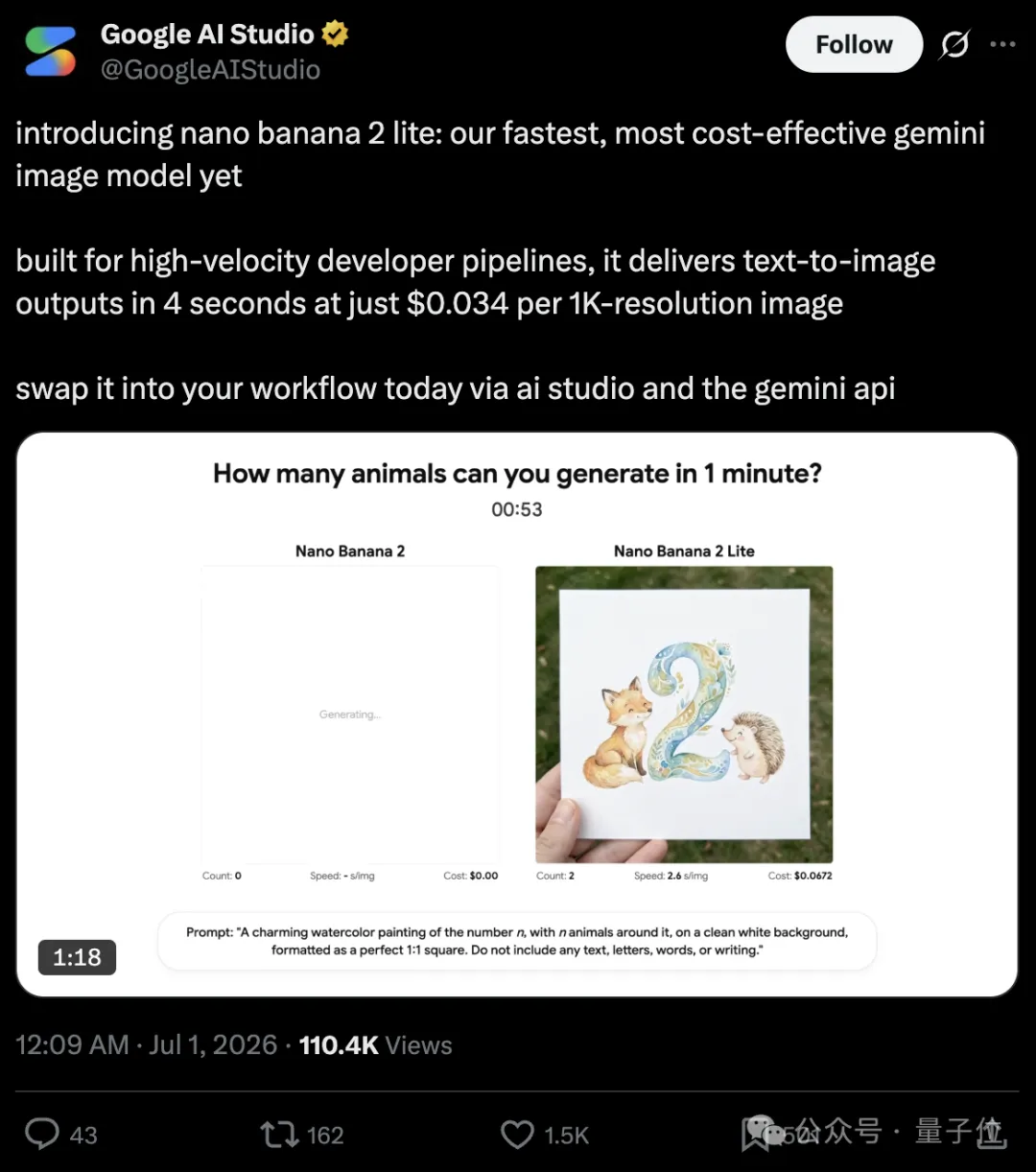
与Omni Flash同步发布的Nano Banana 2 Lite(技术名称gemini-3.1-flash-lite-image),是谷歌迄今最快、成本最低的图像模型。
核心卖点:光速+白菜价
- 出图速度:默认模式下约4秒生成一张图,是标准版Nano Banana 2(约20秒)的五分之一
- 定价:输入每百万tokens 0.25美元,文本和推理输出每百万tokens 1.50美元,图片输出按每百万tokens 30美元计费。生成一张1K图像约0.0336美元(约合0.23元),是标准版的一半、Pro版的四分之一
- 技术原理:基于Gemini 3.1 Flash底层能力进行模型蒸馏与轻量化,采用优化的next-token预测与并行采样策略,支持动态分辨率适配
适用场景与边界
Nano Banana 2 Lite瞄准的是对延迟极度敏感、需要短时间内批量处理大量图像的实时应用场景,如电商素材批量生成、广告创意快速迭代、自动化内容流水线。
但便宜和快速也有边界。Ars Technica提醒,Lite版更适合快速草图和批量试错;如果图片里有小号文字、价格、数据说明,或者需要同一角色在多张图里高度一致,仍应使用更高端模型或人工复核。所有生成图片都会带有SynthID隐形水印。
谷歌官方建议:如果你还在用初代Nano Banana,赶紧换。Lite版在各项关键指标上已经全方位碾压。
三、双剑合璧:1+1>2的魔法Workflow
这次发布真正的亮点,在于将两个模型串联使用。借助Nano Banana 2 Lite高速出图,再把生成的图像作为参考素材喂给Gemini Omni Flash,一键转化为视频,实现图像生成与视频创作的无缝衔接。
谷歌专门做了3个Demo APP展示这套工作流:
- Anywhere:自拍或上传照片,NB2 Lite瞬间把你P到几十个地标景点里,点击图片后Omni Flash把静态景点变成动态短片——赛博旅游端到端实现。
- Space Lift:上传房间照片,NB2 Lite出各种装修风格方案,选定后Omni Flash直接生成电影级空间漫游视频。再结合Genie世界模型,未来可能威胁传统装修方案SaaS公司。
- Omni Product Studio:给产品拍白底图,NB2 Lite出场景化商品图,Omni Flash再把静态图变成电商短视频,从”产品”到”广告素材”全链路自动跑完。
这套工作流解决了AIGC创作中反复迭代、素材管理麻烦的痛点,无需反复上传文件。
四、多模态到底有什么用?谷歌的商业化答案
在2026年,Coding几乎等同于模型智商的代名词,每家都在Coding上往死里卷。谷歌死磕多模态,图什么?
短期来看,谷歌这套多模态模型确实能赋能旗下不少产品:Stitch、Pixel内置的P图、NotebookLM等。这次发布的两个新模型,更让人看到了多模态在垂直场景落地的潜力——电商、装修、短视频这些业务的需求是真的,钱也是真的。
加上安卓生态加持,谷歌在Android 17和Wear OS 7中全面集成Gemini Omni及Lyria3多模态模型,基本不用太担心商业化的问题。
从技术演进看,Gemini Omni Flash是Gemini主架构的进化,将此前独立的视频(Veo)、图像(Nano Banana)、音乐(Lyria)及交互(Genie)生成与理解能力融合进单一模型框架,首次使模型同时具备了理解世界和生成世界的能力。这种原生多模态编码设计,让所有模态共享统一语义表示空间,实现跨模态信息无缝转换。
Coding谷歌暂时追不上,但多模态这张牌桌,谷歌可能是唯一能组齐一套牌的玩家。
五、行业影响与展望
Gemini Omni Flash的开放API,意味着视频生成正式进入生产级应用阶段。其MoE架构天然支持参数规模的线性扩展,当未来需要处理更复杂的多模态输入时,只需增加新的”专家模块”,不会因参数爆炸导致延迟飙升。这决定了它不是过渡方案,而是面向未来三年的生产基座。
对工程团队而言,专家建议先用Google Cloud Vertex AI的托管端点跑完MVP,确认prompt-to-video的品质稳定度后再考虑私有化部署——Flash版的蒸馏架构虽然轻量,但对prompt的敏感度比Pro更高,微小的措辞差异可能导致输出品质大幅波动。
至于大家心心念念的Gemini 3.5 Pro到底什么时候来?这个问题,恐怕连哈萨比斯本人也还没准备好回答。
文章来源:本文综合自量子位、百度百科、CSDN、HitPaw、网易智能、AI工具集、搜狐科技、腾讯新闻等多个公开信息源,原文首发于2026年7月1日。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...