
Kimi K2.6
Kimi K2.6 是月之暗面(Moonshot AI)推出...
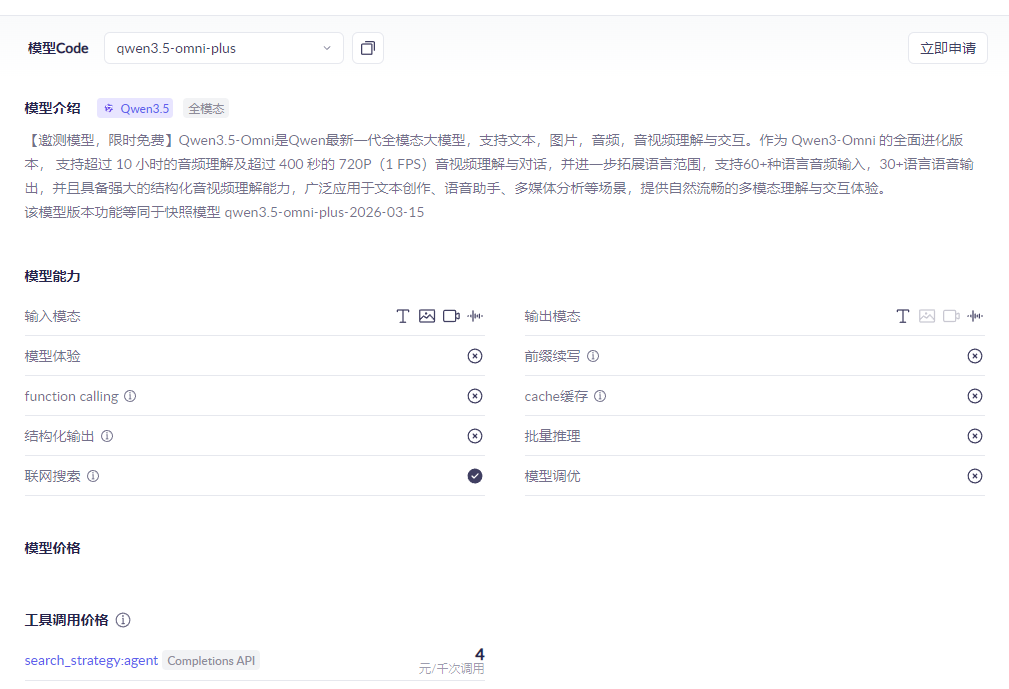
Qwen3.5-Omni是Qwen最新一代全模态大模型,支持文本,图片,音频,音视频理解与交互。
Qwen3.5-Omni 是阿里通义千问团队于 2026 年 3 月正式发布的新一代全模态大模型,原生支持文本、图像、音频及音视频输入,输出文本与语音,采用 Thinker-Talker 分工架构与 Hybrid-Attention MoE 混合专家结构,在 215 项音频/音视频理解与交互任务上取得 SOTA 成绩,在通用音频理解、推理、识别、翻译与对话等指标上全面超越 Gemini-3.1 Pro,音视频理解总体达到 Gemini-3.1 Pro 水平,同时文本与视觉能力与同尺寸 Qwen3.5 模型持平。模型支持 256K 长上下文、超过 10 小时音频输入与约 1 小时 720P 视频输入,支持 113 种语言及方言语音识别、36 种语言及方言语音生成,并具备语义打断、音色克隆、语音控制、ARIA 动态对齐、WebSearch 与 Function Call 等实时交互能力,以及自然涌现的 Audio-Visual Vibe Coding(音视频编程)能力,可广泛应用于内容创作、音视频理解、智能客服、会议纪要、多语言交互等场景。普通用户可在 Qwen Chat 免费体验,开发者和企业可通过阿里云百炼平台调用 Qwen3.5-Omni Plus/Flash/Light 三种尺寸 API,每百万 Tokens 输入成本不到 0.8 元,约为 Gemini-3.1 Pro 的十分之一。
Qwen3.5-Omni 是 Qwen3.5 系列中的“全模态(Omni)”版本,定位为高性价比、全场景适配的工业级全模态大模型,与仅支持文本或图文的多模态模型不同,Qwen3.5-Omni 原生支持文本、图像、音频、音视频四种模态的统一理解与生成。全模态大模型:指能够在一个统一模型框架内同时理解并生成文本、图像、音频、视频等多种模态内容的大模型,而非简单拼接多个单模态模型。
Qwen3.5-Omni 系列提供三种尺寸的 Instruct 版本,覆盖不同性能与成本需求:
Instruct 版本:指经过指令微调、对齐人类指令的版本,更适合对话、工具调用等应用场景,而非仅用于底层特征提取。
Qwen3.5-Omni 采用 Thinker-Talker 分工架构:Thinker 负责多模态理解,接收视觉与音频信号并通过 TMRoPE 编码位置信息;Talker 负责语音生成,基于 Thinker 输出采用 RVQ 编码实现高效语音合成,两者协同实现理解与生成分离,避免传统“先语音转文本再理解”的信息损失。
Thinker-Talker 架构:一种将“理解模块(Thinker)”与“表达模块(Talker)”显式分离的模型结构,理解模块专注于跨模态推理,表达模块专注于自然、稳定的语音或文本生成。
Thinker 与 Talker 均采用 Hybrid-Attention MoE 架构,将听、看、理解等任务分配给不同专家网络,避免模态间干扰,在保持文本与视觉能力基本不下降的前提下,大幅提升音频与音视频任务性能,共取得 215 项 SOTA 成绩。
Hybrid-Attention MoE:一种混合注意力机制的混合专家模型,通过稀疏激活多个专家网络,在参数规模可控的前提下提升模型对不同模态和任务的适配能力。
Qwen3.5-Omni 在海量文本、视觉数据以及超过 1 亿小时音视频数据上进行原生多模态预训练,从源头提升跨模态理解与生成的一致性与稳定性,而非在单模态模型之上外挂语音或视频接口。
原生多模态预训练:指模型从预训练阶段就同时学习文本、图像、音频、视频等多种模态数据,而不是先训练文本模型再“拼上”视觉或语音编码器。
端到端全模态处理:用户上传一段音视频,模型直接在统一空间内理解画面、声音、字幕等信息,并输出文本或语音,无需中间流水线。
长上下文能力:指模型能够一次性处理超长文本或超长音视频内容,保持全局依赖关系,适合长会议、长播客、长电影等场景。
多语言多方言支持:模型在语音识别与语音合成层面覆盖主流语种与方言,适合跨境客服、多语言内容创作等场景。
在第三方基准测试中,Qwen3.5-Omni-Plus 在音频与音视频理解、推理与交互任务上共取得 215 项子任务 SOTA 成绩,涵盖:
其中,通用音频理解、推理、识别、翻译及对话能力全面超越 Gemini-3.1 Pro,音视频理解能力总体达到 Gemini-3.1 Pro 水平。
Qwen3.5-Omni 具备可控、详细、结构化的音视频 Caption 能力,可对视频内容进行:
结构化音视频描述:模型输出带时间戳的“剧本式”脚本,可直接用于视频检索、审核、二创脚本生成等生产流程。
通过原生多模态 Scaling,模型涌现出根据音视频指令直接进行编程的能力,即 Audio-Visual Vibe Coding:用户在摄像头前展示草图、口述需求,模型可生成带复杂 UI 的产品原型界面或网页代码,实现“边看边说边写代码”。
Vibe Coding:一种通过自然语言或音视频交互直接生成可执行代码或原型界面的交互方式,用户无需编写详细代码,只需描述意图即可。
Qwen3.5-Omni 在实时交互层面新增多项能力:
普通用户可直接访问 Qwen Chat 在线体验 Qwen3.5-Omni 的全模态能力:
适用场景:个人用户快速体验音视频理解、实时语音对话、Vibe Coding 等能力,无需编写代码。
开发者和企业可通过阿里云百炼平台调用 Qwen3.5-Omni 的 API,构建自己的应用。
import os
import base64
import soundfile as sf
import numpy as np
from openai import OpenAI
# 1. 初始化客户端
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ,
)
# 2. 发起请求
completion = client.chat.completions.create(
model="qwen3.5-omni-plus",
messages=[{"role": "user", "content": "你是谁"}],
modalities=["text", "audio"], # 指定输出文本和音频
audio={"voice": "Tina", "format": "wav"},
stream=True,
stream_options={"include_usage": True},
)
# 3. 处理流式响应并解码音频
audio_base64_string = ""
for chunk in completion:
if chunk.choices and chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="")
if chunk.choices and hasattr(chunk.choices[0].delta, "audio") and chunk.choices[0].delta.audio:
audio_base64_string += chunk.choices[0].delta.audio.get("data", "")
# 4. 保存音频文件
if audio_base64_string:
wav_bytes = base64.b64decode(audio_base64_string)
audio_np = np.frombuffer(wav_bytes, dtype=np.int16)
sf.write("audio_assistant.wav", audio_np, samplerate=24000)
print("\n音频文件已保存至:audio_assistant.wav")

(以上示例基于阿里云官方文档简化整理)
本站大国Ai提供的Qwen3.5-Omni都来源于网络,不保证外部链接的准确性和完整性,同时,对于该外部链接的指向,不由大国Ai实际控制,在2026年4月2日 下午12:43收录时,该网页上的内容,都属于合规合法,后期网页的内容如出现违规,可以直接联系网站管理员进行删除,大国Ai不承担任何责任。