GPT-4
GPT-4是OpenAI于2023年3月发布的第四代生成式预训练语言模型,支持文本与图像输入,输出高质量文本内容。它在逻辑推理、代码生成、多模态处理等领域表现卓越,并通过强化安全性和上下文理解能力,成为企业级AI应用的重要工具。GPT4官网入口: https://www.chatgpt.com/gpt4
编程推理多模态全面升级,代理式AI能力突破性进展
【摘要】2026年4月24日,OpenAI正式发布新一代大语言模型GPT-5.5。该模型被官方定义为”迄今最智能、最直观的模型”,在编程能力、推理水平、多模态理解及代理式任务执行方面实现显著提升。GPT-5.5基于NVIDIA GB200/GB300 NVL72系统训练,上下文窗口达100万token,支持端到端实时内容安全监测。模型现已面向ChatGPT Plus、Pro、Business及Enterprise用户开放,同时提供API接入。
GPT5.5官网入口:chatgpt.com
ChatGPT开发者平台:platform.openai.com
2026年4月24日,OpenAI首席执行官山姆·奥特曼(Sam Altman)通过官方博客及社交平台X宣布推出GPT-5.5。该模型定位为OpenAI当前能力最强的通用大语言模型,也是GPT-5系列的重要迭代版本。按照OpenAI的产品演进路线,GPT-5.5承接GPT-5、GPT-5.1(2025年11月)、GPT-5.2(2025年12月)、GPT-5.3(2026年3月)的技术积累,在保持与前代GPT-5.4相当响应速度的前提下,实现了智能密度的实质性跃升。
官方将GPT-5.5描述为”迈向计算机上完成工作的新方式的下一步”,强调其在代理式AI(Agentic AI)方向的能力突破。与前代模型相比,GPT-5.5的核心改进在于能够更快理解用户意图,自主承担更多任务执行工作,减少人工逐步干预的需求。
GPT-5.5基于NVIDIA GB200与GB300 NVL72高性能计算系统进行训练。该系统采用NVLink全互连架构,提供高带宽、低延迟的算力支持,使模型能够在更大规模的数据集上进行深度训练。OpenAI表示,GPT-5.5在训练过程中优化了令牌效率(Token Efficiency),在完成同等编程任务时,其消耗的令牌数量较GPT-5.4明显减少,直接转化为API调用成本的降低。
模型采用端到端实时内容安全监测架构,这是OpenAI首次将此类机制集成到主流商用大模型中。该设计旨在应对日益复杂的滥用风险与全球监管要求,在保障模型能力开放的同时,建立更强的安全防线。
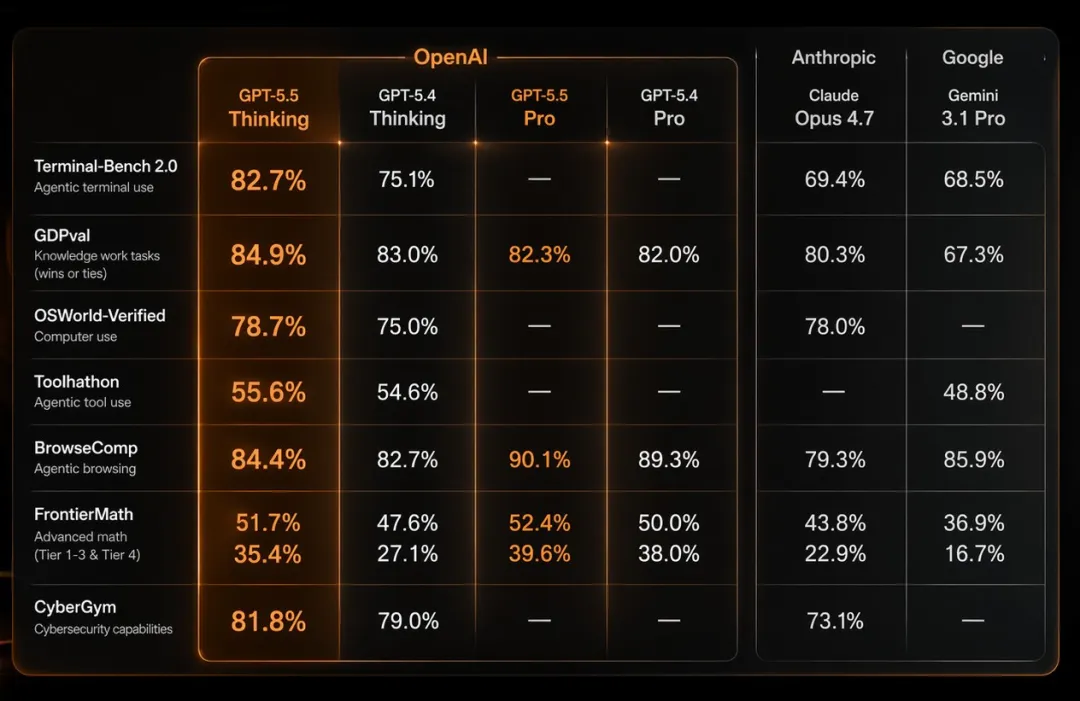
GPT-5.5在编程领域的表现是本次升级的核心亮点。模型在SWE-Bench Pro(GitHub问题解决的权威基准)上达到58.6%的准确率,在Terminal-Bench 2.0(命令行工作流测试)上达到82.7%。对于预计需要20小时完成时间的复杂编程任务(Expert-SWE内部评估),GPT-5.5取得73.1%的成绩,显示出处理大规模、长周期开发任务的潜力。
在实际应用中,GPT-5.5支持编写和调试代码、在线调研、数据分析、创建文档和电子表格、操作软件等多种任务类型。模型能够在任务执行过程中持续切换工具,自主检查中间结果,并在遇到模糊需求时进行合理推断而非中断执行。
GPT-5.5的推理能力在多个维度上得到强化。在GDPval基准(覆盖44种职业知识工作)上,模型获得84.9%的分数;在OSWorld-Verified(计算机环境操作能力评估)上达到78.7%。这些数据表明,GPT-5.5不仅在纯文本推理上表现优异,还能够将推理能力有效迁移到涉及图形界面操作的复杂场景中。
模型引入了改进的链式思维(Chain-of-Thought)追踪机制,能够更透明地展示推理过程。用户可以通过观察模型的思考路径,判断结论的可靠性,并在必要时进行干预或修正。
GPT-5.5延续并扩展了GPT-4o系列建立的多模态处理能力。模型能够同时处理文本、图像、音频等多种输入形式,并在不同模态之间进行信息整合与交叉推理。在MMMU(学院水平视觉问题)等视觉理解基准上,GPT-5系列此前已达到84.2%的水平,GPT-5.5在此基础上进一步优化了图表解读、演示文稿分析和视频内容理解的准确率。
值得注意的是,GPT-5.5的语音交互模式仍由GPT-4o提供底层支持,这表明在多模态实时响应方面,OpenAI采取了”专项模型负责专项任务”的技术策略,而非依赖单一模型处理所有输入类型。
GPT-5.5在工具调用(Function Calling)方面实现重要突破。模型支持更长的工具调用链,能够在复杂工作流中保持高稳定性。根据OpenAI此前公布的测试数据,GPT-5在工具调用基准上的容错率和长链执行稳定性已显著优于GPT-4系列,GPT-5.5在此基础上进一步优化了调用效率和错误恢复能力。
对于企业开发者而言,这意味着GPT-5.5更适合构建需要多步骤、多工具协作的自动化流程,例如:从数据采集、清洗、分析到报告生成的全链路自动化,或跨多个SaaS平台的业务流程编排。
以下表格汇总了GPT-5.5在主要技术基准上的测试成绩,以及与前一版本GPT-5.4的对比:
| 基准测试 | GPT-5.5 | GPT-5.4 | 测试维度 |
| Terminal-Bench 2.0 | 82.7% | — | 命令行工作流 |
| SWE-Bench Pro | 58.6% | — | GitHub问题解决 |
| Expert-SWE | 73.1% | — | 复杂编程任务(20h) |
| GDPval | 84.9% | — | 44种职业知识工作 |
| OSWorld-Verified | 78.7% | — | 计算机环境操作 |
| GeneBench | 25.0% | 19.0% | 基因研究 |
| BixBench | 80.5% | — | 生物信息学分析 |
从数据可以看出,GPT-5.5在编程类任务(SWE-Bench Pro、Expert-SWE)和科研类任务(GeneBench、BixBench)上进步最为明显。在保持与GPT-5.4相同延迟水平的前提下,这些性能提升主要源于模型架构优化和训练数据质量的改进,而非单纯增加参数量。
GPT-5.5搭载了OpenAI迄今最强的安全防护体系。模型在发布前经过了全面的安全评估,包括内部红队测试、外部安全研究者的独立审计,以及近200个早期访问合作伙伴的真实场景反馈收集。
根据OpenAI的准备框架(Preparedness Framework),GPT-5.5在生物安全(Bio Risk)和网络安全(Cybersecurity)两个维度的能力评级均为”高”(High)。针对这两项能力,OpenAI实施了额外的访问控制措施:通过”可信网络访问”(Trusted Network Access)计划,仅向经过验证的安全专业人员提供专门访问权限。
模型首次集成端到端实时内容安全监测系统,能够在生成内容的同时进行安全检测,而非事后过滤。这一机制大幅降低了有害内容的漏检率,同时减少了对正常使用的误拦截。OpenAI表示,该设计旨在”减少滥用,同时保留有益工作的访问权限”。
GPT-5.5已通过多个渠道向用户开放:
模型的上下文窗口为100万token,可处理约75万汉字的单次输入,适用于长文档分析、大型代码库理解等场景。
GPT-5.5提供两个API版本,定价策略延续了OpenAI”能力越高、定价越高”的分层模式:
| 版本 | 输入($/百万token) | 输出($/百万token) | 上下文窗口 |
| GPT-5.5 | $5 | $30 | 100万token |
| GPT-5.5 Pro | $30 | $180 | 100万token |
| GPT-5 | $1.25 | $10 | 标准 |
| GPT-5.3 Instant | $0.50 | $2 | 标准 |
与GPT-5系列其他版本相比,GPT-5.5的定位介于标准版与Pro版之间。GPT-5.5标准版(输入$5/百万token)的定价高于GPT-5(输入$1.25/百万token)和GPT-5.3 Instant,但远低于GPT-5.5 Pro(输入$30/百万token)。这一定价反映了GPT-5.5在能力密度上的中间定位——比基础版显著更强,但不及Pro版的极限性能。
对于需要处理高复杂度任务的企业用户,GPT-5.5 Pro提供了更高的性能上限,但成本也相应增加约6倍。开发者在选型时需根据任务复杂度、延迟要求和预算约束进行综合权衡。
GPT-5.5的编程能力使其成为企业开发团队的效率工具。典型应用场景包括:自动化代码审查、Bug修复、单元测试生成、遗留代码重构、API文档编写等。模型在SWE-Bench Pro上的58.6%准确率意味着,超过半数的开源项目问题可以由模型自主或半自主地解决。
对于需要处理大规模代码库(超过10万行)的项目,GPT-5.5的100万token上下文窗口提供了显著优势,能够一次性加载整个项目的核心模块进行分析。
GPT-5.5在GeneBench(基因研究基准)和BixBench(生物信息学分析基准)上的优异表现,表明该模型已具备辅助科学研究的能力。研究人员可利用模型进行文献综述、实验设计优化、基因组数据解读等工作。
在数据分析领域,模型支持从原始数据清洗、探索性分析到可视化报告生成的全流程自动化,特别适合需要频繁处理数据但缺乏专职数据分析师的团队。
对于法律、金融、咨询等知识密集型行业,GPT-5.5可用于合同审查、合规检查、市场研究报告撰写等任务。模型在GDPval(44种职业知识工作评估)上的84.9%分数表明其对专业领域知识的掌握程度已达到实用水平。
内容创作者可利用GPT-5.5进行素材收集、大纲构建、初稿生成和编辑优化。需要注意的是,与GPT-4o相比,GPT-5.5的输出风格更偏理性严谨,在需要高度创意和情感共鸣的文学创作场景中,可能不如GPT-4o灵活。
综合各模型特性,建议按以下逻辑进行选型:
GPT-5.5的发布标志着OpenAI在代理式AI方向迈出了关键一步。该模型并非追求参数规模的简单扩张,而是在推理效率、工具调用、安全防护等维度上进行了系统性优化。100万token的上下文窗口、82.7%的Terminal-Bench准确率、以及端到端实时安全监测机制,共同构成了GPT-5.5的技术竞争力。
从产业视角观察,GPT-5.5的推出也反映了当前大语言模型竞争的几个趋势:一是从”模型能力”向”任务完成能力”的转变,用户更关心AI能否真正替代理完成工作而非仅仅回答问题;二是安全与能力同步提升,而非作为事后补救措施;三是定价分层更加精细,以满足不同规模企业和开发者的差异化需求。
对于开发者和企业用户而言,GPT-5.5值得在编程自动化、复杂数据分析、多步骤任务编排等场景中进行试用评估。随着OpenAI持续迭代GPT-5系列模型,以及后续GPT-6等更大版本的技术储备逐步释放,人工智能在知识工作领域的渗透深度将进一步加大。
文章来源与版权说明
本文内容由大国AI导航(daguoai.com)整理编写,基于OpenAI官方发布信息及公开技术资料。
文章版权归大国AI导航所有。转载、引用或节选请注明出处,商业用途请联系授权。
本文仅供参考,不构成任何投资或技术决策建议。模型能力、定价及可用性以OpenAI官方最新公告为准。
最后更新:2026年4月24日
本站大国Ai提供的GPT5.5都来源于网络,不保证外部链接的准确性和完整性,同时,对于该外部链接的指向,不由大国Ai实际控制,在2026年4月24日 上午4:54收录时,该网页上的内容,都属于合规合法,后期网页的内容如出现违规,可以直接联系网站管理员进行删除,大国Ai不承担任何责任。







