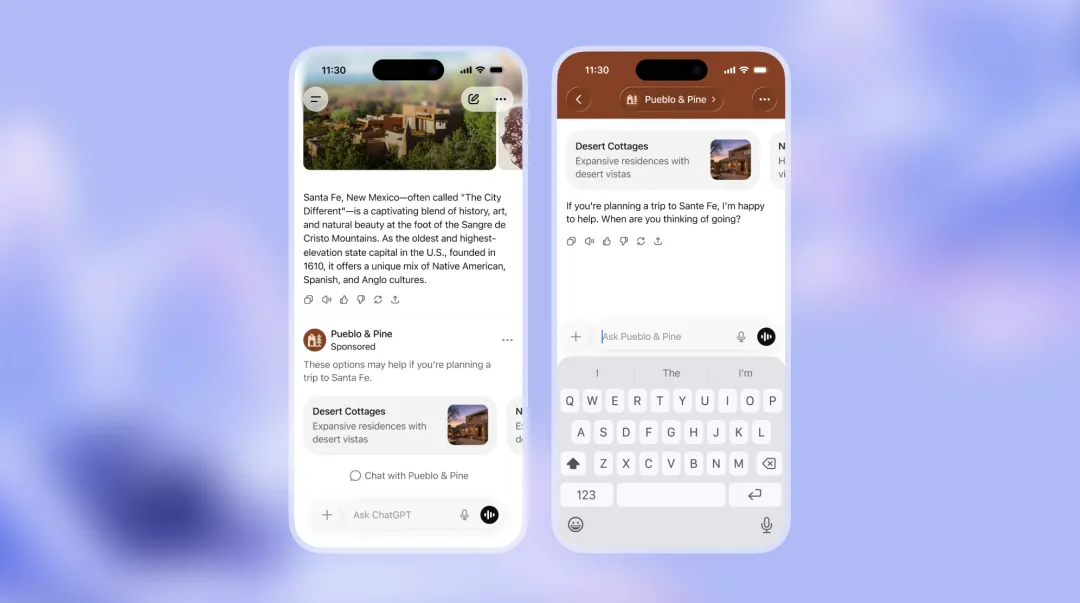
模型在评测中表现卓越,却在现实中犯低级错误,这种脱节现象预示着单纯扩大模型规模的道路已经走到尽头。
大国AI导航(daguoai.com)
2025年11月26日 讯 OpenAI联合创始人、Safe Superintelligence公司首席执行官Ilya Sutskever近日在接受知名播客主持人Dwarkesh Patel专访时宣布:“Scaling时代已经结束,我们正进入研究时代。” 这一重磅声明揭示了人工智能发展路径的根本转变。
在长达1.5小时的深度访谈中,这位AI领域的权威专家几乎揭开了当前AI研究所有最刺痛的真相。他指出,不仅仅是预训练,连Scaling Law这条路也已被判了“缓刑”——虽然还能继续走,但绝不会通向AGI。

01 评估优异与现实滞后:AI能力的“锯齿状”落差
Sutskever开场便感慨道:“想到这一切都是真的,真的有点疯狂!”住在湾区,经常会看到“拿出美国1%GDP投AI、某某公司又投xx美元”这类科幻般的情节。但奇怪的是,一切又好像没有什么变化。
AI模型在智力上实现了飞跃,但它们对经济的实际渗透却慢得多。Sutskever坦言,这正是当前AI最令人困惑的矛盾点:在各种基准评测中,AI模型性能的表现几乎“超乎人们的想象”,但在真实世界中,它却常常犯一些让人抓狂的错误。
他举例说明了一种典型现象:假设你用氛围编程(vibe coding)完成某项任务时遇到一个错误,然后让模型修复,它会遵从指示但在修复过程中又引入新错误。当你指出新错误后,它再次认错,却把原来的错误又带回来了。这种循环往复的情况时有发生,虽然具体原因尚不明确,但这表明系统确实存在某些异常。
为什么会出现在评估表现优异而实际应用效果大打折扣的现象? Sutskever给出了两种解释:
一是强化学习训练让模型过于专注和狭隘,缺乏某种“意识”;二是预训练使用了所有数据,而强化学习训练则需要选择特定的训练环境,设计这些环境时变量过多,可能导致无意中优化了某些评估目标,却忽视了实际应用中的需求。
“真正的‘奖励黑客’其实是那些过于关注评估的人类研究员,” Sutskever尖锐地指出。这意味着,真正钻测评空子的不是模型,而是设计基准和强化学习环境的人类研究者。
02 规模化范式的兴衰:从研究时代到规模化时代,再回归研究
回顾AI发展历程,Sutskever描绘了一幅清晰的图景:从2012年到2020年,是“研究时代”;然后从2020年到2025年,是“规模化时代”。人们看到了预训练的巨大成功,然后说:“这太神奇了,我们必须更多规模化,继续扩大规模。”
预训练最大的突破在于大家意识到:这套规模化“配方”确实有效。你可以把一些计算、一些数据和一个适当大小的神经网络混合在一起,最终得到结果。更妙的是,如果你按比例放大这个配方,你会得到更好的效果。这个发现非常有价值,特别是对于公司来说,因为它提供了一种低风险的方式来分配资源。
但是,数据始终是有限的。到了某个阶段,预训练会耗尽数据。那时候,你该怎么办?Sutskever指出:“现在计算资源的规模已经非常庞大,从某种意义上来说,我们又回到了研究时代。”
我们已经见证了一种规模化方式的转换——从预训练的规模化,切换到了强化学习的规模化。有些人现在在强化学习上的计算投入,可能已经超过了预训练的投入,因为强化学习本身非常消耗计算资源。
但Sutskever质疑道:“我现在甚至不愿称之为‘规模化’。我会问:‘你现在在做的事情,真的是你能做的最有效率的事情吗?你能不能找到一种更高效的方法来利用计算资源?’”
03 泛化能力差距:为什么AI学得又慢又笨?
访谈中最核心的问题指向了AI与人类学习能力的根本差异:泛化能力。Sutskever直言不讳地指出:“这些模型在泛化能力上总是比人类差得多。这是一个非常显著的差异,也是一个根本性的问题。”
为什么这些模型需要这么多数据来学习,而人类则不需要?即使不考虑数据量,为什么教机器学习我们想要的东西要比教人类更难?
Sutskever用了一个比喻来解释这个问题:假设有两个学生,一个决心成为最好的竞技程序员,因此花一万小时练习,解决所有问题,最终成为顶尖选手。另一个学生只练习了一百小时,却也表现得相当好。毫无疑问,第二个学生将会在未来职业生涯发展得更好。
“现在的模型更像第一个学生,甚至更极端。” Sutskever说,“它们就像‘应试专家’。我们为了让它精通编程竞赛,就用海量题目进行填鸭式训练。结果它虽然成了答题高手,却依然难以将所学知识灵活应用到其他任务上。”
预训练的主要优势有两点:第一,数据量巨大;第二,不需要费心选择预训练该用什么数据。这些是非常自然的数据,包含了人类的各种行为、想法和特征。这就像是整个世界通过人类投射到文本上,而预训练试图用海量数据来捕捉这一切。
但与人脑相比,当前AI的样本效率和泛化能力仍然存在数量级上的差距。
04 价值函数:AI的“情绪系统”关键所在
在探讨人类与AI学习差异时,Sutskever提出了一个引人深思的观点:价值函数可能是提高AI学习效率的关键,它类似于人类的情绪系统。
他引用了一个神经科学案例:一个人因为脑损伤破坏了情绪处理能力,不再感受到任何情绪。他仍然善于言辞,能解决一些小难题,在测试中看起来完全正常。但结果,他在做任何决定时都变得极其糟糕,决定穿哪双袜子要花他几个小时,还会做出非常糟糕的财务决策。
“这说明了我们内在的情感在使我们成为可行的智能体方面扮演了重要角色,” Sutskever指出。情绪可能是一种进化过程中硬编码的价值函数,对我们有效行动至关重要。
在技术层面,Sutskever解释道,价值函数的概念类似于:“我可能并不总是能立刻告诉你做得好还是不好,但有时可以提前提醒。”比如,下棋时如果你丢了一个棋子,你立刻就知道自己犯了个错误,不需要等到整场棋局结束才能知道哪一步是错的。
这种反馈可以帮助你更快地调整策略,提高效率。价值函数可以帮助加快找到最终结果的过程,在得到最终解答之前,就已经调整了策略。
当前AI系统缺乏这种内在的价值判断机制,导致学习过程效率低下,容易陷入局部最优。
05 超级智能的时间表与安全挑战
在访谈的后半部分,Sutskever对超级智能的时间表做出了预测:人类级别AGI可能在5到20年内实现。
针对超级智能的安全风险,Sutskever提出了一个独特的观点:构建一个关爱有感知生命的AI,比构建一个仅关爱人类生命的AI要容易。因为AI本身也将是有感知的。他提到镜像神经元和人类对动物的同理心,认为这是一种涌现属性,源于我们使用模拟自己的同一套神经回路去模拟他人,因为那是最高效的方式。
关于AGI的部署策略,Sutskever认为渐进主义将是任何计划与生俱来的组成部分。他形象地比喻:人类好比造出了一个超级聪明的15岁少年,跃跃欲试。他懂的并不多,但他是个好学生,求知若渴。你可以对他说:“去当个程序员,去当个医生,去学习吧。”
因此,部署本身将包含一个通过试错来学习的时期。这是一个过程,而不是直接投放一个“最终成品”。超级智能并不是某种“完成形态”的心智,不需要一上来就懂得如何从事经济活动中的每一项工作。
Sutskever还强调,目前大多数人难以“切身感知”AGI的真正含义,就像年轻人难以真正理解年老的感觉一样。这种认知差距使得AGI的风险难以被充分评估和准备。
随着Scaling时代落下帷幕,AI发展正站在新的十字路口。Ilya Sutskever的见解为我们指明了方向:未来的突破将来自于质而非量,来自于深度思考而非盲目扩张。
在算力资源已经极大丰富的今天,我们确实需要回归研究的本质——探索未知、勇于创新、追求效率与优雅的平衡。只有这样,AI才能真正实现从工具到智能的质的飞跃。
大国AI导航将持续关注AI领域的最新发展,为读者提供权威、前沿的行业洞察。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...