
摘要: 阿里巴巴旗下通义千问团队于2025年12月20日开源了图像模型Qwen-Image-Layered,该模型能实现Photoshop级别的图像自动分层分解,将单张图片拆解为多个可独立编辑的RGBA透明图层。这一技术突破直接指向图像编辑领域的核心工作流程,有望为婚纱摄影、电商美工、UI设计、影视后期等重度依赖精细抠图与图层处理的行业带来显著的效率变革。模型及相关代码、训练方法已在GitHub及Hugging Face平台开源,可免费使用。
一、技术突破:从“像素修改”到“图层解构”的范式革命
传统AI图像编辑工具多集中于风格迁移、滤镜应用或基于扩散模型的局部重绘,其本质仍是在像素层面进行操作,修改一处往往“牵一发而动全身”。而Qwen-Image-Layered的发布,标志着AI开始理解并解构图像的内在图层逻辑。
该模型的核心能力在于,能够根据人类指令(Prompt),将一张普通图片(如JPG、PNG格式)分解为3到10个物理隔离的RGBA透明图层。每个图层都对应图像中的一个语义组件(如前景人物、背景建筑、装饰文字等),用户可以像在专业软件(如Adobe Photoshop)中一样,对任意图层进行独立编辑、隐藏、删除或调整,而不会影响其他图层内容。更关键的是,模型支持“无限层级递归分解”,即可以对已分解出的图层进行再次分层,实现“俄罗斯套娃”式的精细编辑,理论上可拆解至任意细节深度。
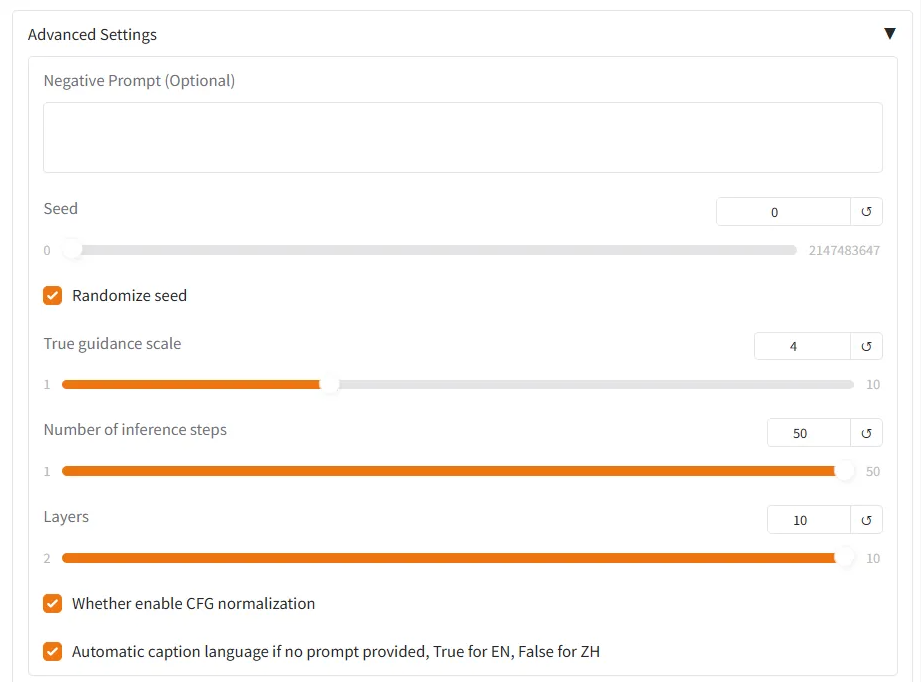
这一能力解决了图像编辑中长久以来的核心痛点:非结构化图像的后期修改成本高昂。无论是去除照片中的多余人物、更换电商海报的促销文案,还是调整UI设计中的按钮颜色,以往都需要设计师手动进行复杂、耗时的抠图操作。Qwen-Image-Layered通过AI自动理解图像语义并分层,将这一过程自动化,实现了从“手工精修”到“智能解构”的跨越。
二、应用场景:多行业工作流面临效率重塑
该技术的开源,预计将对多个依赖图像处理的行业产生直接冲击,其价值主要体现在“降本增效”与“能力平民化”两个方面。
- 婚纱摄影与旅游摄影:影楼提供的精修照片数量有限,消费者若想对大量原图进行个性化调整(如替换背景、去除路人),往往需要寻求外部修图服务。现在,用户可将生图导入该模型,快速分解图层后自行编辑,大幅降低了后期处理的技术门槛和经济成本。
- UI/UX设计与电商美工:设计师频繁面临的需求变更(如调整元素颜色、位置、文案)是重复劳动的重灾区。以往修改一张复杂合成图,需要在海量图层中精准定位。如今,通过指令让AI直接分解出目标元素所在的独立图层,修改效率将得到指数级提升。对于电商美工而言,为同一商品主图制作不同促销版本(如换文案、调背景)的工作将变得极其简便。
- 影视后期与内容审核:影视抠像(如去除绿幕、替换背景)是劳动密集型工作。虽然当前模型主要处理静态图像,但其技术路径为视频逐帧自动分层提供了明确的可能性。此外,在需要快速处理涉事人物图像的内容场景下(如因艺人问题需下架相关物料),该技术能极大加速“去人化”流程。
三、生态影响:开源策略加速技术普及与行业进化
Qwen-Image-Layered选择完全开源,其模型、代码乃至训练方法均在GitHub和魔塔社区公开。这一策略与通义千问一贯的开源路线一脉相承,旨在快速推动技术普及和生态构建。
- 降低使用门槛:任何个人开发者或企业均可免费下载模型,进行本地化部署或二次开发,无需支付高昂的软件授权费用。官方在Hugging Face平台提供了可即时体验的Demo,用户上传图片并可选填指令,即可在线体验分层效果。
- 激发行业创新:开源使得专业软件公司、在线设计平台、云服务商能够基于此模型,快速开发或集成更智能的图像编辑功能,从而催生新的在线工具和商业模式。这类似于AI写作工具对内容生产领域的改造,将专业能力工具化、平民化。
- 对传统软件业的挑战:该模型直指Adobe Photoshop等专业软件的核心价值——图层管理。尽管在功能的全面性和专业性上,AI模型短期内尚无法完全替代历经数十年发展的工业级软件,但它无疑在“自动化”和“易用性”这两个维度上构成了降维打击,迫使传统软件商必须加速融合AI能力以维持竞争力。
四、未来展望:AI如何深度赋能创意工作流
Qwen-Image-Layered的出现,是AIGC(人工智能生成内容)向“结构化内容理解与编辑”纵深发展的一个标志性事件。它表明,AI不再满足于生成新的内容,而是开始深度理解现有内容的构成,并赋予其可编程、可编辑的属性。
从更宏观的媒体内容生产视角看,这与新闻生产领域引入AI进行素材整理、初稿撰写、风格转换的趋势异曲同工。正如AI可以辅助记者快速转换新闻视角、重组文章结构,或帮助编辑进行海量稿件分类与舆情分析,Qwen-Image-Layered也是在帮助视觉内容创作者从繁琐的底层操作中解放出来,使其能更专注于创意本身。
然而,技术始终是工具。正如资深编辑在利用AI提示词模板提升写作效率时所指出的:“AI负责‘执行’,人负责‘把关’”。图像分层模型的输出结果仍需人工进行审美判断和最终调整,复杂场景下的分解精度也可能存在误差。未来的方向将是“人机协同”,AI处理标准化、重复性的解构任务,人类则主导创意决策与质量把控。
结语
通义千问Qwen-Image-Layered模型的开源,不仅是一个技术成果的发布,更是向整个图像处理生态投下的一颗“深水炸弹”。它通过将Photoshop的核心能力——图层编辑——AI化、自动化、免费化,正在重新定义图像后期处理的效率标准。对于相关行业的从业者而言,积极拥抱并学习利用此类工具,将其转化为提升自身竞争力的“加速器”,或许是在这场效率革命中保持领先的关键。
文章来源:本文综合自通义千问官方开源信息、技术社区讨论及行业分析,核心事实来源于2025年12月20日相关技术发布报道。同时,结合了AI赋能内容生产、机器学习在新闻领域的应用等跨领域发展趋势进行的延伸解读。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...