
摘要: 通义实验室近日推出长文本推理专家模型QwenLong-L1.5,该模型基于Qwen3-30B-A3B打造,通过一套包含高质量数据合成、稳定强化学习训练及突破性记忆管理框架的系统性后训练方案,在多项权威基准测试中实现了与GPT-5、Gemini-2.5-Pro等顶级旗舰模型相媲美的性能。尤为关键的是,其能力提升并非“偏科”,反而促进了数学推理、智能体记忆等通用能力的增强,并展现出处理百万至千万级Token超长文本的潜力,为AI在代码分析、财报解读、专业文献研究等复杂场景的实用化落地提供了关键技术支撑。
引言:从“大海捞针”到“全局洞察”,长文本推理的实用化突破
在人工智能技术迅猛发展的当下,大模型的长文本处理能力已成为衡量其智能水平的关键标尺。然而,许多模型在标准“大海捞针”测试中表现优异,却在需要串联多处信息、进行多跳推理的真实复杂任务中力不从心。同时,长文本、多任务数据的复杂性常导致强化学习训练过程不稳定,而有限的物理上下文窗口更是制约了模型处理海量信息的能力。
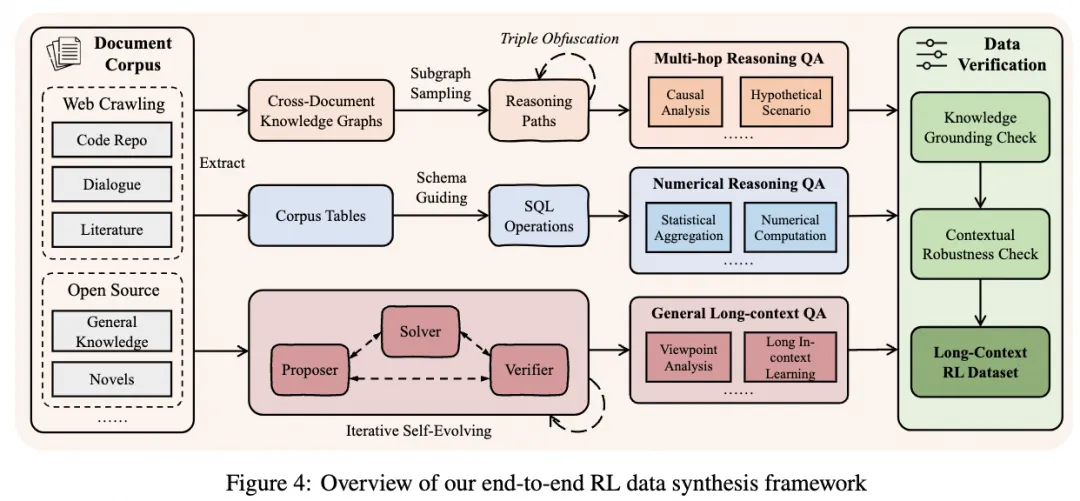
针对这些行业共性挑战,通义实验室发布的QwenLong-L1.5并非简单的参数扩展或局部优化,而是提出了一套端到端的系统性解决方案。该方案旨在从根本上重塑模型处理长文本的“思维方式”,使其从被动的信息检索者,转变为能进行深度关联、逻辑推理和全局理解的“思考者”。
技术核心:三大“法宝”构建系统性优势
QwenLong-L1.5的成功源于其三大核心技术突破,它们共同构成了一个完整的学习与推理增强闭环。
法宝一:可编程的高质量数据合成流水线 模型的“智商”取决于其训练的“食粮”。QwenLong-L1.5摒弃了简单的问答对数据,构建了一条能自动生成复杂推理任务的数据合成流水线。该流水线包含三大引擎:
- 知识图谱引导引擎:自动挖掘文档间的深层逻辑链,生成需要跨段落、跨文档关联思考的多跳推理问题。
- 跨文档表格引擎:从多个非结构化文档中抽取并整合数据,生成需要进行聚合、统计与复杂计算的数值推理题。
- 多智能体自我进化框架:通过“出题者”、“解题者”、“检验者”智能体的协同工作,基于无标签文档自动合成任务,并迭代提升任务难度与广度。
这套方法确保了模型在训练中接触的是高度模拟真实世界复杂性的挑战,从而习得真正的深度推理能力。
法宝二:应对异构与信度分配难题的强化学习策略 在长文本、多任务的强化学习训练中,数据分布的异构性和信用分配不准确是两大核心难题。QwenLong-L1.5通过创新算法予以解决:
- 针对数据异构:采用任务均衡采样和任务专属优势估计,确保不同任务类型的样本在训练批次中均匀分布,并为每种任务提供稳定、准确的奖励信号,避免了因数据分布剧烈偏移导致的训练不稳定。
- 针对信用分配:提出自适应熵控制策略优化算法。该算法能根据模型自身的不确定性(熵),动态决定是否对错误答案施加惩罚。当模型在高不确定性下探索犯错时,保护其探索欲;当其在高度自信下依然犯错时,则坚决纠正。这有效平衡了探索与利用,防止了训练崩溃。
法宝三:超越物理窗口的记忆管理智能体框架 面对远超上下文窗口的超长文本(如整个代码库、长篇专著),QwenLong-L1.5引入了记忆管理框架。这相当于为模型配备了一个可无限扩展的“外置大脑”或“智能笔记本”。模型在阅读时,能主动进行迭代式记忆更新,形成结构化摘要,并在需要时高效检索。通过多阶段融合强化学习训练,这种“外置记忆”能力与模型固有的“窗口内推理”能力被无缝整合,形成了一个统一的、能处理近乎无限长度信息的智能体。
性能表现:比肩顶级模型,能力全面增强
评测结果显示,QwenLong-L1.5-30B-A3B模型在多项权威长文本推理基准上的平均性能,相比其基线模型Qwen3-30B-A3B-Thinking提升了9.9分,达到了与GPT-5、Gemini-2.5-Pro等业界顶尖闭源模型相媲美的水平。
更值得关注的是,其性能提升精准体现在最考验深度推理能力的任务上。例如,在需要多跳推理和全局信息整合的MRCR、CorpusQA等基准上,性能分别大幅提升了31.72分和9.69分。这直接验证了其可编程数据合成方法的有效性——模型在它被专门训练的复杂任务上表现尤为出色。
此外,长文本专项训练并未导致“偏科”。相反,QwenLong-L1.5在数学推理(AIME25)、智能体记忆(BFCL)以及长对话记忆(LongMemEval)等通用任务上也取得了显著进步,其中长对话记忆能力提升了15.6分。这证明,提升长程信息整合能力是一种基础的“认知升级”,其收益能辐射到多项核心能力。
在征服超长文本的极限测试中,借助记忆管理框架,QwenLong-L1.5在处理128K至4M Token的超长文档任务时,性能显著优于同类智能体方法,展现了强大的可扩展性和处理海量信息流的潜力。
行业背景与价值:赋能千行百业智能化升级
QwenLong-L1.5所攻克的长文本深度理解难题,具有广泛而深远的应用前景。这正契合了当前人工智能与各行业深度融合的大趋势。例如,在新闻传媒领域,AI技术已被用于重构新闻生产流程,优化内容采编分发,甚至自动生成专业稿件。在交通物流领域,行业大模型正深度融合行业知识,为基础设施规划、运输调度等全链条业务提供智能支撑。在国际传播中,AI工具被用于辅助翻译、润色文稿、预测传播趋势,以增强跨文化传播的精准性。
这些场景无一不对AI模型的深度理解、多源信息整合与复杂推理能力提出了更高要求。QwenLong-L1.5通过系统性的技术创新,为模型注入了真正的“读懂”和“思考”长文本内容的能力,有望在代码分析与生成、金融财报深度解读、长篇法律文书研究、学术文献综述、跨文档知识问答等专业领域发挥关键作用,加速AI从“表现型工具”向“深度分析型助手”的演进。
同时,降低大模型的使用成本是推动其规模化应用的关键。此前,阿里云通过大幅降低通义千问等模型的API调用价格,旨在加速AI应用的爆发。QwenLong-L1.5以30B(激活参数3B)的较小参数量实现顶级性能,本身即体现了高效的技术路径,有助于在控制成本的前提下,为更多企业和开发者提供强大的长文本处理能力。
结语
QwenLong-L1.5的发布,标志着长文本AI推理从追求“长度”到追求“深度”的重要转折。它通过一套涵盖数据、训练方法和架构的系统性组合方案,不仅解决了当前模型在长上下文应用中面临的实用化瓶颈,更通过能力泛化证明了深度推理训练的普适价值。随着此类技术的不断成熟与普及,AI将能更可靠地协助人类处理和理解日益增长的海量复杂信息,为各行各业的智能化升级注入新的核心动力。
文章来源:综合自魔搭ModelScope社区发布的《QwenLong-L1.5:让AI真正读懂长文本的秘密武器》技术文章,并参考了人工智能在新闻生产、交通物流、国际传播等领域的应用实践及相关行业动态。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...