
摘要:面对Anthropic旗下Claude Code在AI编程领域掀起的浪潮,OpenAI于2026年1月24日发起强力回应,一次性公布两项核心技术底牌。其一是首次深度揭秘Codex背后的“大脑”——Agent Loop(智能体循环)架构,展示了AI从被动问答转向自主规划执行的飞跃。其二是披露了支撑ChatGPT等核心服务的惊人基础设施:仅凭一个PostgreSQL主数据库节点和约50个只读副本,成功承载了全球8亿用户、每秒数百万次的查询洪峰。这不仅是技术的展示,更是OpenAI在AI Agent成熟度与极致工程能力上的一次标准定义权争夺。
一、 Codex的“大脑”:Agent Loop如何让AI真正“干活”
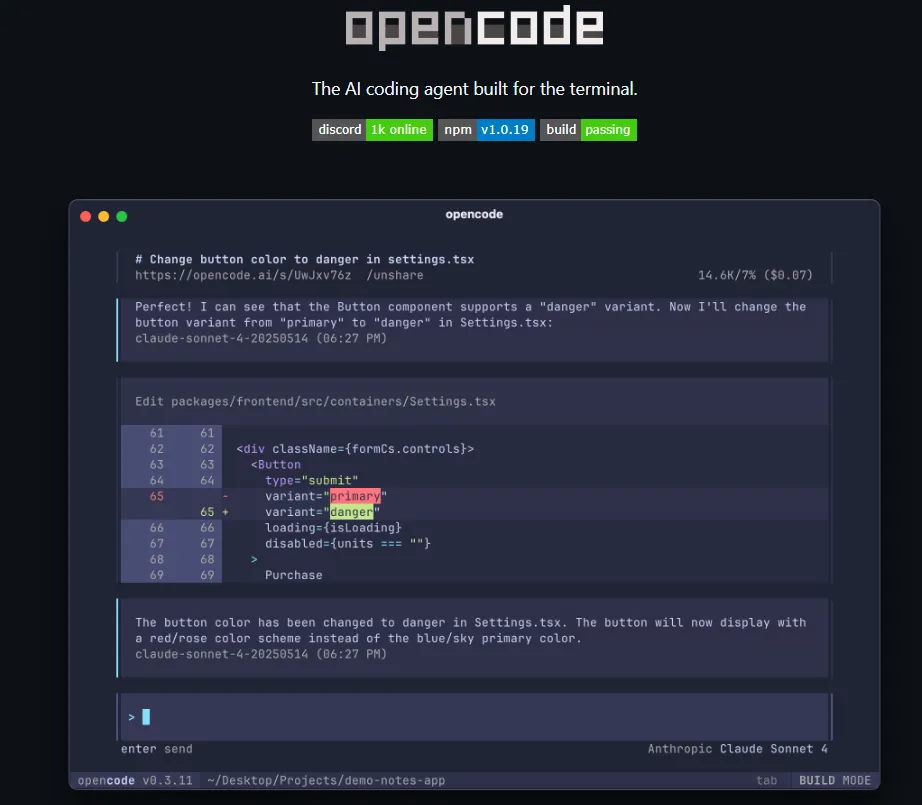
近期,AI编程工具的竞争焦点已从简单的代码补全,转向了能否理解上下文、自主执行复杂任务的“智能体”(Agent)。Anthropic的Claude Code因其能在终端内读取代码、修改文件、运行测试的“虚拟同事”能力而备受赞誉。作为回应,OpenAI首次系统性地公开了驱动Codex的核心机制——Agent Loop。

1.1 什么是Agent Loop?从问答到执行的范式转变
Agent Loop不是一个新功能,而是一套完整的系统架构。它彻底改变了传统大语言模型(LLM)“一问一答”的交互模式,构建了一个 “观察-思考-行动-反馈” 的闭环。简单来说,它就像一个项目“总指挥”,将用户意图、模型推理能力和外部执行工具(如Shell、文件系统)无缝串联起来。
1.2 拆解Agent Loop五步工作流
以一个具体任务“给项目的README.md添加架构图”为例,Codex的“大脑”运转如下:
- 构建Prompt(发工单):Codex不会直接转发用户指令。它会精心组装一个包含系统角色定义、可用工具列表、当前环境上下文和用户指令的完整Prompt,为模型提供充足的行动依据。
- 模型推理(思考):模型接收Prompt后开始规划,例如决定先调用
cat README.md命令查看现有内容。 - 工具调用(执行):Codex接收模型指令,在安全沙箱中执行相应的Shell命令或文件操作。
- 结果反馈:工具执行的结果(如文件内容)被追加到对话历史中。
- 循环迭代:模型基于新上下文再次推理,可能决定生成Mermaid代码并写入文件。此循环持续进行,直至模型判定任务完成。
这个过程的关键在于,AI不再是被动响应,而是在主动解决问题,具备自主规划、错误检查和结果验证的能力。
1.3 攻克Agent工程两大难题:成本与记忆
实现高效的Agent Loop面临巨大工程挑战,OpenAI分享了两项关键优化:
- 痛点一:成本爆炸。Agent每轮循环都需携带全部历史对话和工具输出,导致Token消耗和推理成本呈平方级增长。
- 解决方案:提示词缓存(Prompt Caching)。采用前缀匹配缓存策略,只要Prompt开头的系统指令、工具定义等静态内容不变,即可复用之前计算结果,将成本压降至线性增长。但此机制极为敏感,早期曾因工具列表顺序不稳定导致缓存频繁失效。
- 痛点二:上下文窗口限制。处理大型项目时,上下文易被填满,导致AI“遗忘”前期任务。
- 解决方案:对话压缩(Compaction)。当Token数超阈值时,不是简单删除旧消息,而是调用特殊接口将历史对话压缩成一段加密的摘要(
encrypted_content)。这相当于生成一张“记忆卡片”,让模型在保留关键语义逻辑的前提下继续处理超长任务,支持单次任务连续运行7小时以上。
- 解决方案:对话压缩(Compaction)。当Token数超阈值时,不是简单删除旧消息,而是调用特殊接口将历史对话压缩成一段加密的摘要(
这些优化表明,OpenAI的Agent已不是一个实验性功能,而是配备了缓存、压缩、安全沙箱的“操作系统级”成熟产品。
二、 8亿用户背后的工程奇迹:PostgreSQL的极限扩展
当业界热议AI模型能力时,OpenAI曝光了其更令人震撼的基础设施实力:支撑ChatGPT和API全球流量的,竟是一个未分片(unsharded)的单一PostgreSQL主库。
2.1 反潮流的极简架构
在分布式、微服务盛行的今天,OpenAI采用了看似“复古”的架构:1个主节点(Primary) + 近50个跨地域只读副本(Read Replica)。这套架构完美契合了ChatGPT“读多写少”的业务特性(用户发消息可能触发数十次读,但仅几次写),通过极致的读写分离和读路径优化,将传统关系型数据库的性能推至物理极限。
2.2 关键优化技术拆解
为实现百万级QPS(每秒查询数)和低延迟,OpenAI实施了一系列硬核优化:
- PgBouncer连接池:将数据库连接建立的平均时间从50毫秒降至5毫秒以下,在高并发下意义重大。
- 缓存锁定机制:当缓存失效时,仅允许一个请求穿透至数据库查询并回填缓存,其他请求等待,有效防止“缓存雪崩”击穿数据库。
- 精细化查询优化与负载隔离:识别并重构了涉及多达12张表连接的昂贵查询,将复杂逻辑移至应用层。同时,将请求按优先级隔离到专用实例,避免低优先级任务影响核心服务(解决“吵闹邻居”问题)。
- 跨地域级联复制:读流量被分发至全球各地的副本,实现就近访问,降低延迟。
2.3 触及天花板与未来演进
OpenAI也坦诚,该架构已接近极限。主要瓶颈源于PostgreSQL的MVCC(多版本并发控制)机制带来的写放大、存储膨胀问题,以及随着副本数量增加,WAL(预写日志)复制带来的网络压力。 为此,他们的演进策略是:
- 迁移高写负载:将可自然分片的高写入负载(如某些日志、事件数据)迁移至Azure Cosmos DB等分布式系统。
- 测试级联复制:探索让副本之间接力转发WAL,以支持超过100个副本的更大规模。 这一案例深刻诠释了“如无必要,勿增实体”的架构哲学:在达到真正瓶颈前,一个优化到极致的单机方案,远比过早引入复杂分布式系统更可靠、更高效。
三、 Codex vs. Claude Code:技术路线与生态之争
OpenAI此次组合拳,直接对标了近期引发轰动的Claude Code。两者的竞争已超越功能对比,上升到技术路线和生态话语权的层面。
- Claude Code的优势:被定位为“项目级别的智能合作者”。它原生深度集成MCP(模型上下文协议)工具,开箱即用,在终端内提供同步、交互式的开发体验,适合需要实时反馈和紧密协作的场景。
- Codex的差异化:通过公开Agent Loop,OpenAI强调了其异步、自主执行的能力。Codex更像一个“远程员工”,可接收一个高级任务后在云端独立运行数小时,无需用户持续监督,适合大型重构、代码审计或复杂Bug排查。此外,其公布的网络安全评估能力(如在React源码中发现高危漏洞)展示了在安全敏感任务上的潜力。
如何选择? 对于日常边写边调的开发,Claude Code可能更顺手;对于需要甩手托付的复杂、耗时长任务,Codex的异步模式价值凸显。许多开发者选择两者搭配使用,以最大化效率。
四、 结语:一场定义未来的竞赛
OpenAI此次技术披露,传递出三个清晰信号:
- 工程体系深度:证明其护城河不仅是模型,更包括能支撑行星级应用的成熟工程架构。
- Agent成熟度:展示了一个具备完整规划、执行、优化循环的智能体系统,而非功能拼凑。
- 生态与标准:旨在定义AI编程工具的未来标准和发展范式。
这场由Claude Code引爆、OpenAI强力接招的竞争,正在加速AI从“编程助手”向“自主工程师”的演进。最终,持续的技术透明化与创新竞赛,将为全球开发者带来更强大、更可靠的工具,推动整个软件工程行业向智能化深度转型。
文章来源:本文综合编译整理自OpenAI官方工程博客(2026年1月)、新智元、东方财富网财富号、ITBear科技资讯、InfoQ、CSDN博客及相关技术社区于2026年1月24日左右的报道与分析。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...