
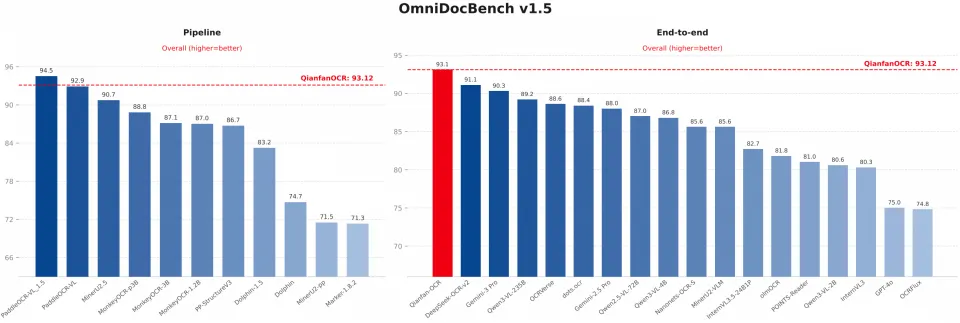
摘要:2026年3月19日,百度智能云千帆大模型平台正式推出革命性的端到端文档智能模型——Qianfan-OCR。这款模型彻底抛弃了传统OCR“检测、识别、理解”的多段式流水线,采用统一的4B参数视觉语言架构,将文档解析、版面分析、文字识别与语义理解四大能力融为一体。其在权威评测中表现惊艳,不仅在OmniDocBench v1.5上以93.12分位列端到端模型榜首,其关键信息抽取(KIE)能力甚至超过了Google Gemini 3-Pro等顶级商用模型。这标志着文档智能处理正式从“流程拼接”迈入“模型统一”的新时代。
如何获取与使用:三大渠道,即刻体验
对于开发者和企业而言,获取并使用Qianfan-OCR的路径非常清晰。百度提供了从云端服务到开源代码的全套方案:
- 千帆平台直接调用:模型已在百度智能云千帆大模型平台上线。千帆平台作为企业级一站式大模型服务平台,提供了丰富的模型库、组件和开发工具。用户可以直接在平台调用该模型的API,快速集成到自己的业务应用中。
- 开源社区下载:秉承百度在AI开源领域的积极策略,Qianfan-OCR的模型权重已在HuggingFace上开源,研究人员和开发者可以自由下载、研究与再创作。
- 获取配套技能(Skills):为了进一步降低使用门槛,百度在GitHub上发布了配套的“Qianfan-OCR文档智能skills”。用户可以将这些预置技能像插件一样加载到自己的AI智能体(如“小龙虾”)中,轻松实现文档转化与理解等复杂任务,真正做到“为你的小龙虾加点技能,秒变小神龙”。
核心功能与优势:为什么说它是“范式革命”?
传统的工业级OCR系统就像一个分工明确的流水线,需要多个模型接力完成:检测模型先框出位置,识别模型再读出文字,最后交给大模型去理解。这套模式成熟,但问题也明显:流程长、误差会累积、部署复杂,最关键的是,当文本从图片中被“抠”出来后,原有的版面、图表结构等视觉上下文就丢失了,严重制约了对复杂文档的理解深度。
Qianfan-OCR的突破在于,它用一个端到端模型完成了上述所有工作。其核心优势对比一目了然:
| 特性维度 | 传统Pipeline OCR | 百度千帆Qianfan-OCR |
|---|---|---|
| 技术架构 | 多模型串联(检测→识别→理解) | 单一模型端到端(视觉语言统一模型) |
| 处理流程 | 复杂,需异构编排(CPU+GPU) | 极简,只需一个vLLM实例 |
| 信息保留 | 文本与视觉上下文分离,结构信息易丢失 | 完整保留视觉与结构信息,理解更准确 |
| 核心创新 | – | Layout-as-Thought机制:将版面分析内化为模型“思考”步骤,显式建模文档结构 |
| 部署效率 | 低,资源消耗大 | 高(单张A100,W8A8量化下吞吐达1.024页/秒) |
| 输出结果 | 通常为纯文本,需后处理 | 直接输出结构化结果(Markdown、JSON、HTML等) |
简单来说,Qianfan-OCR让模型学会了“先看版式,再读内容”。它通过独特的 <think> Layout</think> 思考令牌,在生成最终答案前,先在内部对文档的排版、元素位置和阅读顺序进行推理和建模。这使得它在处理多栏文档、复杂表格、图表等场景时,表现出远超传统方法的鲁棒性和准确性。
适用场景与价值:让AI真正读懂你的“文件筐”
这项技术革新将直接赋能大量需要处理非结构化文档的行业,解决实际痛点:
- 金融与政务:自动解析复杂的报表、合同、票据和申报材料,精准抽取关键字段(如金额、日期、条款),完成智能审核与归档,将人力从繁琐的重复劳动中解放。
- 教育与科研:一键解析学术论文、教材中的图表、公式和排版内容,辅助进行知识梳理、题库生成和高质量学习资料数字化,让知识获取更高效。
- 企业办公与知识管理:将公司内部海量的历史文档(Word、PDF、扫描件)快速转化为可搜索、可分析的结构化数据,构建企业知识库,提升决策效率。
- 医疗与法律:快速理解病历、检查单、法律文书等专业文档,辅助完成信息摘要、合规性检查,为专业人士提供强有力的AI助手。
百度此次发布Qianfan-OCR,不仅是推出一款高性能模型,更是将其置于千帆大模型平台的整体战略中。通过提供从顶尖模型、开源代码、便捷技能到强大算力(如自研昆仑芯)的全栈服务,百度正致力于降低AI应用门槛,推动端到端文档智能这一先进范式在千行百业中快速落地,兑现其“用科技让复杂的世界更简单”的使命。
文章来源:综合自百度智能云官方发布、魔搭ModelScope社区报道及相关行业分析。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...