
摘要:2026年4月,AI巨头Anthropic扔下了一颗“重磅炸弹”——Claude Opus 4.7正式上线。它被官方称为“迄今能力最强的通用可用模型”,在编程、金融分析、视觉理解等多方面实现了巨大飞跃。但这不仅仅是一个“更聪明”的模型,它的使用逻辑也发生了关键变化。本文将带你全面了解这款“明星模型”的核心能力,并告诉你如何调整使用方法,真正榨干它的性能,避免“升级了却用不好”的尴尬。
一、 核心升级:不止于“更强”,而是“更稳、更准、更独立”
Opus 4.7并非在所有方面都泛泛地提升,它的进化集中在几个对生产力影响巨大的维度,旨在成为一个可靠的“数字同事”。
- “强迫症”般的指令遵循:这是最显著的行为变化。以前的模型可能会“揣摩”或跳过你指令中模糊的部分,但4.7会严格按字面意思执行。这既是好事也是挑战:好处是输出更可控、更严谨;挑战是,过去那些为旧模型“会意”习惯而调的提示词可能需要重写,否则可能得到意外结果。
- “火眼金睛”的视觉能力:它的图像识别长边支持高达2576像素(约375万像素),是前代的三倍多。这不仅仅是“看得更清”,而是为了让它能看懂软件界面、密集表格和代码截图,为真正的“计算机使用”(Computer Use)能力铺路。在涉及UI操作的基准测试中,成功率从57.7%大幅提升至87.6%。
- “资深专家”级的专业表现:
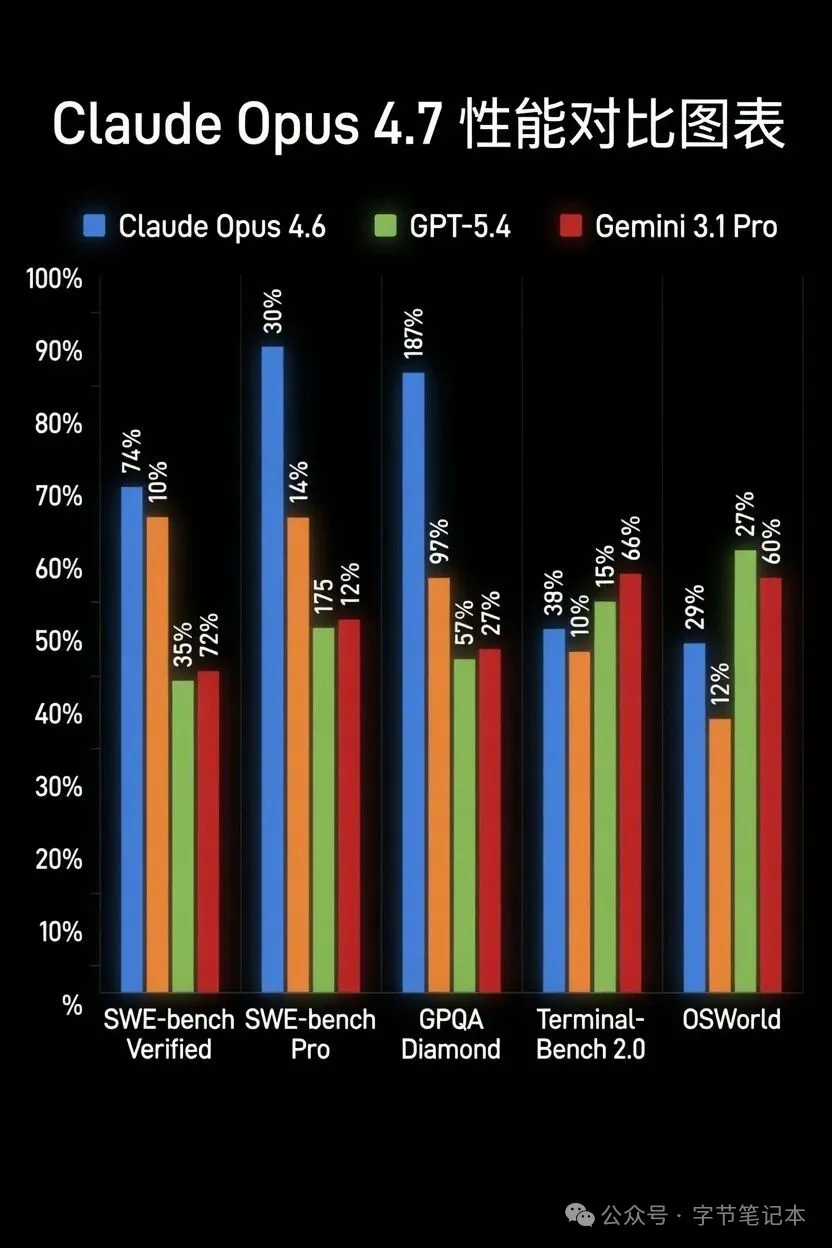
- 编程:在权威的SWE-bench Pro测试中,得分从4.6的53.4%飙升至64.3%,超越了GPT-5.4。它不仅能处理复杂任务,还会在输出前主动验证结果,甚至提前自我纠错。
- 金融与法律:在Finance Agent测试中取得领先分数,能生成更严谨的分析与模型。在法律条款辨析(BigLaw Bench)等高难度任务中,准确率高达90.9%。
- 长时记忆:能更好地利用文件系统记忆,在跨会话的长任务中记住关键笔记,减少重复交代上下文的麻烦。
- “安全先行”的克制策略:Anthropic主动削弱了4.7的网络安全攻击能力,作为其“玻璃翼”安全计划的一部分。模型内置了自动拦截高风险请求的机制。对于合法的安全研究,则需要申请加入专门的验证计划。这体现了Anthropic“能力越强,责任越大”的审慎态度。
二、 使用教程:告别旧习惯,解锁新姿势
直接套用Opus 4.6的使用方法,可能无法发挥4.7的全部实力,甚至会觉得“更费钱”。掌握以下几个关键调整,体验会截然不同。
- 理解“自适应思考”,善用努力等级:
- Opus 4.7用自适应推理取代了固定的“深度思考”开关。它会根据问题难度,自动决定投入多少“脑力”。这意味着总体效率更高,但你也需要学会引导。
- 努力等级(Effort)是新核心控制杆:
- xhigh(新增/默认推荐):介于high和max之间,是日常复杂任务(如代码设计、审查)的甜点区。
- high:成本与性能的平衡点,适合多任务并发。
- medium/low:对响应速度和成本敏感的场景,即使低档位下,4.7表现也优于4.6。
- max:应对极致难题,但可能有边际收益递减,慎用。
- 优化交互模式:一次性说清楚,减少打断
- 首轮指令至关重要:尽量在第一轮对话中,就把目标、约束、验收标准和相关文件路径交代完整。信息越全,模型输出质量越高,总Token消耗可能反而更少。
- 减少中途插话:每次用户输入都会触发模型进行额外推理,增加成本。尽量把问题批量处理,或给予足够上下文让它自主决策。
- 学会放手,使用自动模式:对于长任务,可以开启Auto Mode(目前向Max等高级用户开放),让模型在安全范围内自行做出小决策,大幅减少“是否允许执行”的打断,实现近乎“无人值守”的运行。
- 利用配套新功能,提升工作流效率
/fewer-permission-prompts技能:自动扫描历史会话,推荐将那些安全但总触发确认的常用命令加入白名单,一劳永逸。/ultrareview命令:进行严格的代码审查,像资深同事一样挑出Bug和设计问题。- 进度回顾(Recaps):长时间任务中断后,它能提供简短摘要,帮你快速接上进度。
- 任务预算(API功能):为长任务设定一个Token消耗总预算,让模型学会“精打细算”。
三、 最佳应用场景:把这些任务交给它
结合其能力升级,以下几类任务是Opus 4.7的“主场”:
- 复杂软件工程:跨多文件的重构、遗留代码迁移、生产级Bug修复。有测试者用它生成了1700行代码且零Bug。
- 深度代码审查:对整个项目或服务进行架构级、安全性的全面审查。
- 模糊需求调试:当Bug报告描述不清时,它能更好地推断可能原因并提出验证方案。
- 长时Agent工作流:需要数小时运行、多步骤的数据处理、研究或集成测试任务,配合Auto模式效果极佳。
- 专业内容创作与解析:生成高质量、有“审美”的演示文稿和文档;解析复杂的技术图表、财务表格或法律文件。
价格与获取:官方定价与4.6一致(输入$5/百万Token,输出$25/百万Token)。但需注意,因其使用新分词器和更深思考,相同内容消耗的Token可能会增加10%-35%。它已登陆Claude官网、App、官方API及亚马逊、谷歌、微软的云平台。国内开发者可通过兼容Anthropic协议的API服务节点进行访问。
文章来源:本文信息综合自Anthropic官方发布及多家科技媒体评测,包括腾讯新闻、投资界、搜狐、东方财富网、网易、站长之家及开发者博客等对Claude Opus 4.7的报道与分析。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...