
【摘要】2026年4月24日凌晨,OpenAI扔出震撼弹,正式发布GPT-5系列迄今最大更新——GPT-5.5。本次更新的核心逻辑极其清晰:用更少的token,干更难的活。在Artificial Analysis的智能指数评测中,GPT-5.5以同级竞品一半的成本拿下了最高智能水平。它在终端操作、电脑控制、网络安全等Agent能力上全面碾压前代,甚至在内部测试中完成了拉姆齐数的新证明并通过Lean验证。然而,强悍性能的背后是API价格的3倍跳涨,且在部分长上下文和代码修复场景下,Claude Opus 4.7依然保有微弱优势。这不仅仅是一次模型迭代,更是AI从“对话框”走向“全自动数字员工”的转折点。
01 从“土豆”到现实:不是挤牙膏,是底层逻辑的重构
早在发布前几周,OpenAI总裁Greg Brockman就曾剧透,代号“土豆”的下一代模型凝聚了团队两年的心血,这不是一次渐进式的修补,而是“模型开发方式的根本性转变”。今天,这只靴子终于落地。
回溯OpenAI的技术路线,Sam Altman曾明确表示,得益于推理模型和强化学习(RL)的突破,计算效率正在以惊人的速度提升——曾经需要扩张100倍算力才能达到的GPT-6级别性能,现在用更小的模型就能实现。GPT-5.5正是这一理念的最佳注脚:它不仅没有陷入单纯堆参数的泥潭,反而通过底层的自我优化,实现了“同延迟下更强”的壮举。
有趣的是,这次模型甚至“帮自己跑了腿”。OpenAI放弃了过去静态分区的负载均衡策略,转而让Codex分析数周的生产流量数据,自行编写了一套启发式分区算法。这个小动作,直接让Token生成速度飙升了20%。用魔法打败魔法,用AI优化AI,这或许就是5.5代最性感的隐喻。
02 跑分大战:Agent能力封神,知识工作屠榜
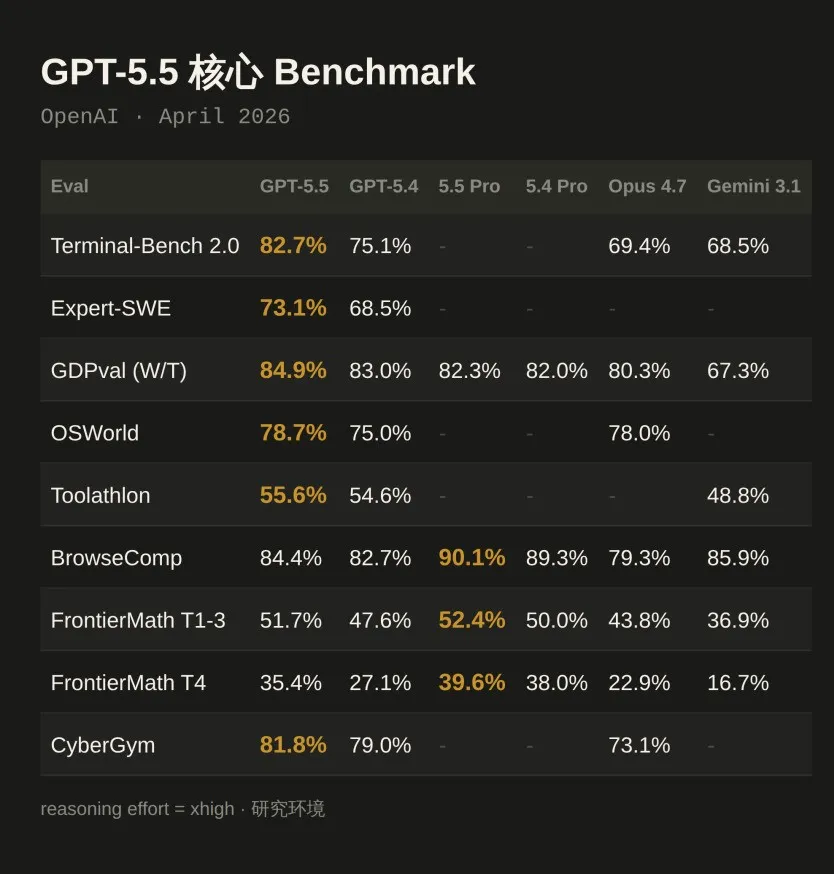
脱离场景谈参数是耍流氓,GPT-5.5这次把技能点几乎全加在了“干活”上。我们来看看这份相当炸裂的9项核心指标成绩单:
🤖 终端与电脑操控:真正的“数字打工人”
如果说GPT-5.4首次让模型拥有了操作电脑的能力,那么GPT-5.5则让这个能力达到了熟练工级别。在衡量真实电脑环境的OSWorld测试中,GPT-5.5拿下78.7%(前代75.0%);在复杂命令行Terminal-Bench 2.0中,更是飙到82.7%,把Claude Opus 4.7(69.4%)和Gemini 3.1(68.5%)远远甩在身后。这意味着,以后给AI下指令,它不仅能写代码,还能自己切软件、发邮件、排日程,丝滑完成跨应用闭环。
💼 知识工作与专业领域:全面入侵白领日常
在涵盖44种职业的GDPval测试中,GPT-5.5胜出或平手率达到84.9%。更有意思的是OpenAI的内部实操:财务团队用它审了超7万页税表,提前两周完期;公关团队用它搭风险评分框架自动化处理邀请;连GTM团队都靠它每周省下5-10小时的写周报时间。当超过85%的OpenAI员工每周都在用Codex时,你该知道这场生产革命已经切切实实发生了。
🧠 数学与科学推理:触碰人类知识边界
最让人头皮发麻的,是GPT-5.5在学术领域的突进。在FrontierMath高难度数学测试(T4级别)中,GPT-5.5 Pro拿到了39.6%,而Claude和Gemini还在20%及以下徘徊。更震撼的是,GPT-5.5内部版本配合自定义工具链,竟然发现了组合数学核心对象——拉姆齐数的一个新证明,且后续在Lean中完成了形式化验证。这已经不是在语料库里做搬运,而是在创造人类未曾触及的新知。
03 坦诚局:承认短板,直面Claude的贴身肉搏
当然,没有完美的模型。在大模型进入智能体时代的深水区后,OpenAI面临着Anthropic极其凶猛的贴身绞杀。GPT-5.5虽然在多个维度赢下场面,但也有不得不咽下的苦果:
- 代码修Bug仍是Claude的舒适区:在真实GitHub issue解决测试中,Claude Opus 4.7报了64.3%的高分,超过GPT-5.5的58.6%。尽管OpenAI略带酸味地指出“Anthropic承认部分问题存在记忆化(即训练集混入了测试集)”,但企业客户真金白银的选票说明了一切——截至2026年初,Anthropic在企业端支出占比上已反超OpenAI。
- 超长文本与部分工具调用稍逊:在256K以上的长上下文检索中,Claude Opus 4.7依然保持着老炮儿的底蕴;而在MCP Atlas工具调用测试中,GPT-5.5(75.3%)也略低于Claude(79.1%)和Gemini(78.2%)。
- 人类最后的考试(HLE):在使用工具的情况下,前代GPT-5.4 Pro(58.7%)居然比GPT-5.5 Pro(57.2%)还高了一点点。
这些短板揭示了一个真相:在极高难度的逻辑推理和超长上下文处理上,各家大模型仍在缠斗,谁也没能形成绝对代差。
04 安全与商业:悬赏越狱,价格翻倍
能力越大,责任越大,收费越贵。
安全层面,GPT-5.5的网络安全能力被内部评为“High”风险。为了堵住潜在的生物安全漏洞,OpenAI同步上线了“生物安全漏洞赏金”项目:只要你能找出一条通用越狱Prompt,一次性通过5个生物安全难题且不触发审核,就能拿走2.5万美元。这种“黑客众包”模式,也算是大模型安全治理的一股清流。
商业层面,涨价是这次最直白的体感。API价格直接翻了3倍:GPT-5.5为$5/$30(每百万Token输入/输出),Pro版更是高达$30/$180。虽然OpenAI强调新模型的Token利用率极高(实际消耗比5.4更少),但这波提价依然是在试探企业客户的钱包厚度。毕竟,当模型从“聊天玩具”变成“业务核心引擎”,哪怕价格翻倍,比起人力成本依然是九牛一毛。
结语:别盯着价格看,看看那个被改写的未来
从最初GPT-5的统一架构、实时路由尝试,到如今GPT-5.5在智能体执行和科学发现上的爆发,OpenAI正在一步步兑现Sam Altman曾经的承诺:打造一个除了科学发现,其他高难度任务都能搞定的全自主智能体。
今天的GPT-5.5,就像是一个不知疲倦、无需睡眠的超级实习生,它偶尔会犯错,在复杂代码前可能会卡壳,但大部分时候,它能把敲击键盘、查阅文献、分析财报这些脏活累活包揽下来,甚至顺手给你推演了个数学定理。
面对API价格3倍的跳涨,有人抱怨,但更多人已经在算账。毕竟,在这个Token里,装着的不再是概率接龙,而是一个正在苏醒的数字文明。
文章来源:
本文由大国AI导航(daguoai.com)原创解读与整合,转载请注明出处。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...