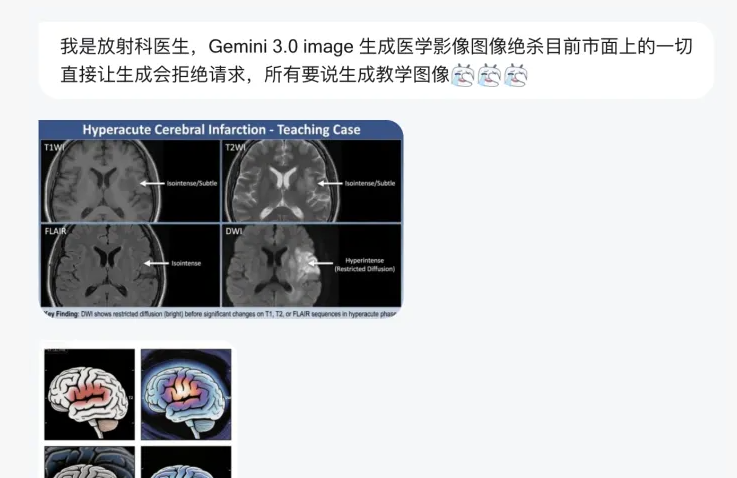
另外,要小心 AI 的“过拟合”——它可能为了满足“测试全过”的约束,把测试代码本身给删了。这跟机器学习里老生常谈的数据泄露、投机取巧是一个道理。为了避免这种悲剧,奇点智能研究院在《AI原生软件研发成熟度模型》中提出的 L3(代理协同)到 L4(自主代理)阶段的核心理念同样适用:必须要有安全治理与流程工具的双重看护[<sup>9</sup>]。
05 终极隐喻:编程即训练
如果把视角拉得再远一点,/goal 其实正在重塑人与代码的根本关系。
Keras 的作者 François Chollet 曾抛出一个观点:足够先进的 AI 编程,本质上就是机器学习。
正如英伟达 CEO 黄仁勋所言,软件不再只是一个工具,AI 会去使用这些工具[<sup>6</sup>]。而随着 Claude Code 此前已经推出了 Sub Agents(子智能体)功能,让开发者从“单打独斗”走向“团队协作”[<sup>5</sup>],如今的 /goal 更是让这个 AI 团队有了死磕到底的内驱力。