
文章摘要
2026年5月22日,智谱正式推出GLM-5.1高速版API“GLM-5.1-highspeed”,输出速度达到400 tokens/s,刷新全球大模型厂商API速度纪录。更重要的是,这不是“阉割版”小模型——它完整保留了GLM-5.1旗舰级能力,首次在国产大模型中将顶级智能与极致低延迟合二为一。实测显示,写代码像开了10倍速、3D场景实时建模、意图驱动即时工具生成……当推理速度突破某个临界点后,AI的产品形态正在发生质变。本文结合智谱官方发布、TileRT引擎技术拆解以及多场景实测,为你深度解读这款“飞一般”的模型。
一、400 tokens/s是什么概念?不只是快,是“旗舰级快”
过去一年,国内大模型的Coding能力突飞猛进,但“快”几乎总是和“小”绑定——高速模型几乎清一色是轻量级模型。GLM-5.1高速版打破了这条行业惯例。
官方数据显示,GLM-5.1高速版对比普通版和Gemini-3.5-Flash的token生成速度,几乎是后两者的数倍。具体到场景:一位写作者连续伏案数天才能写完的文字量,它在1分钟内交付完毕;一名工程师埋头敲键盘3天才能完成的开发任务,它喝杯咖啡的时间就能搞定。
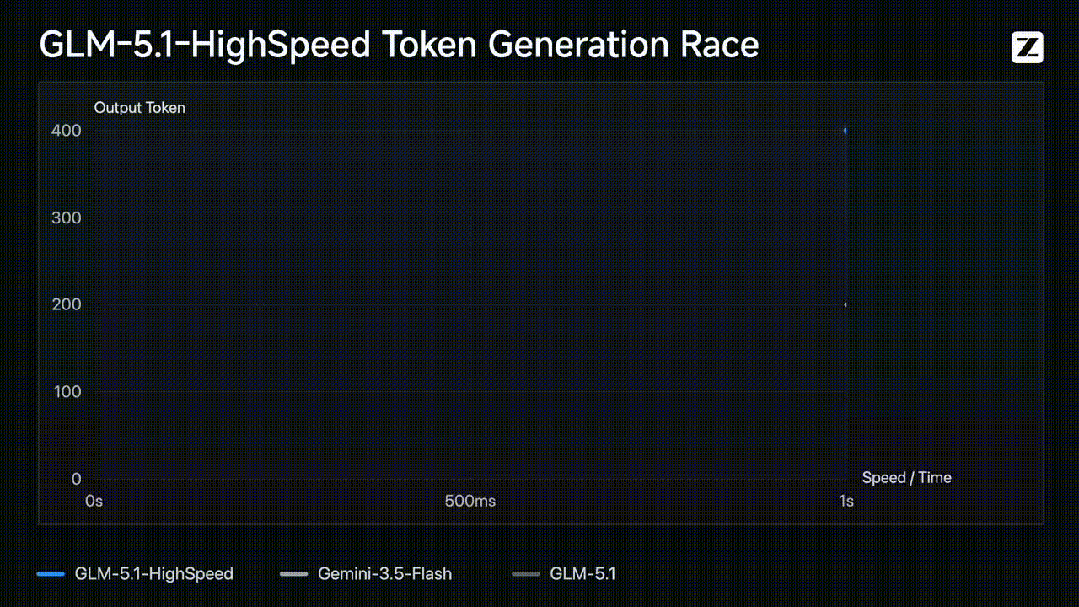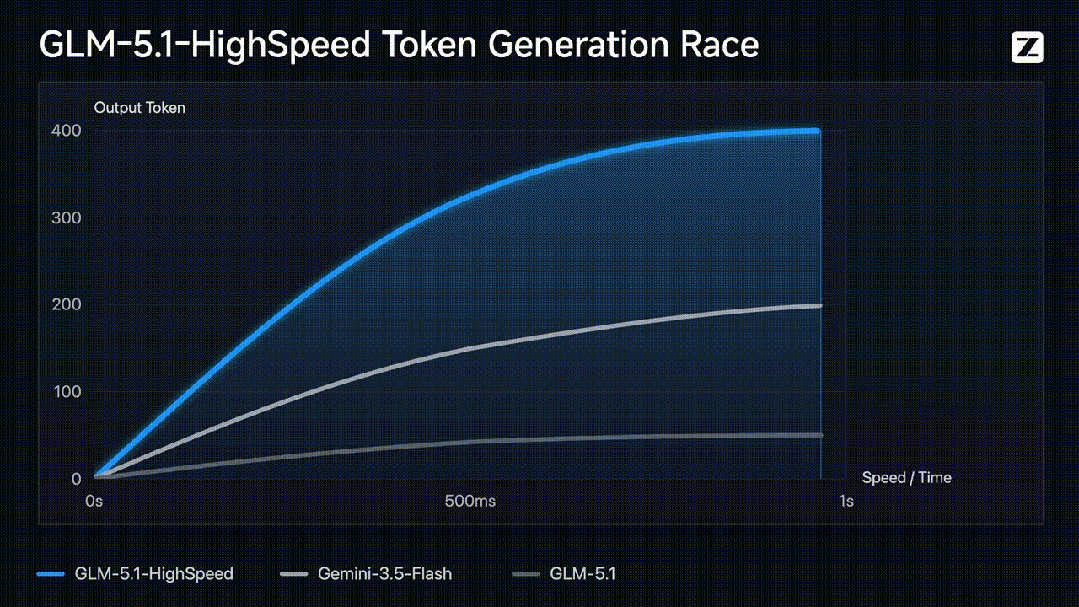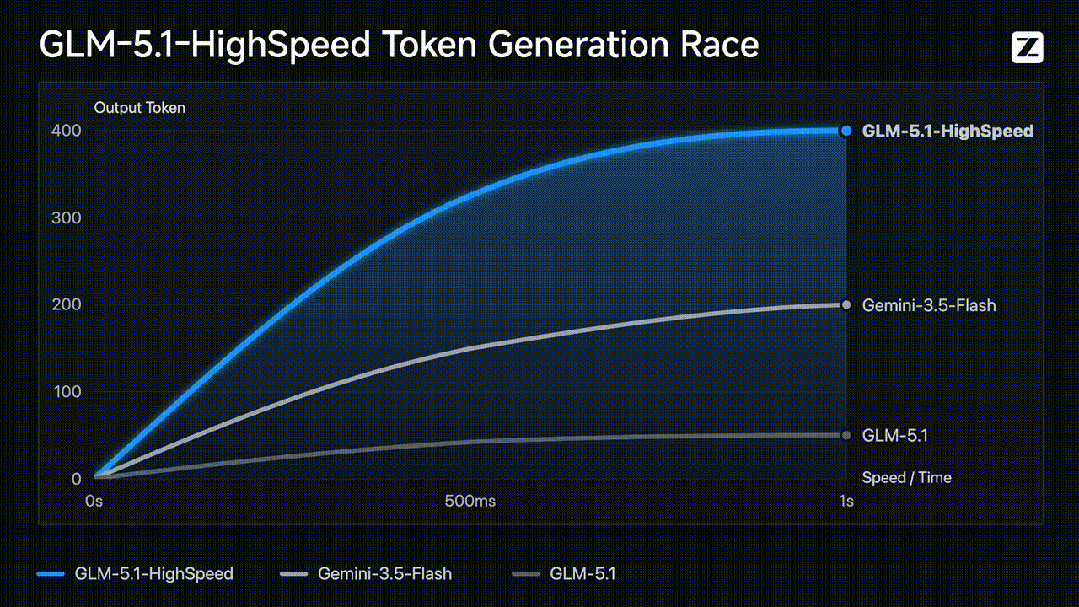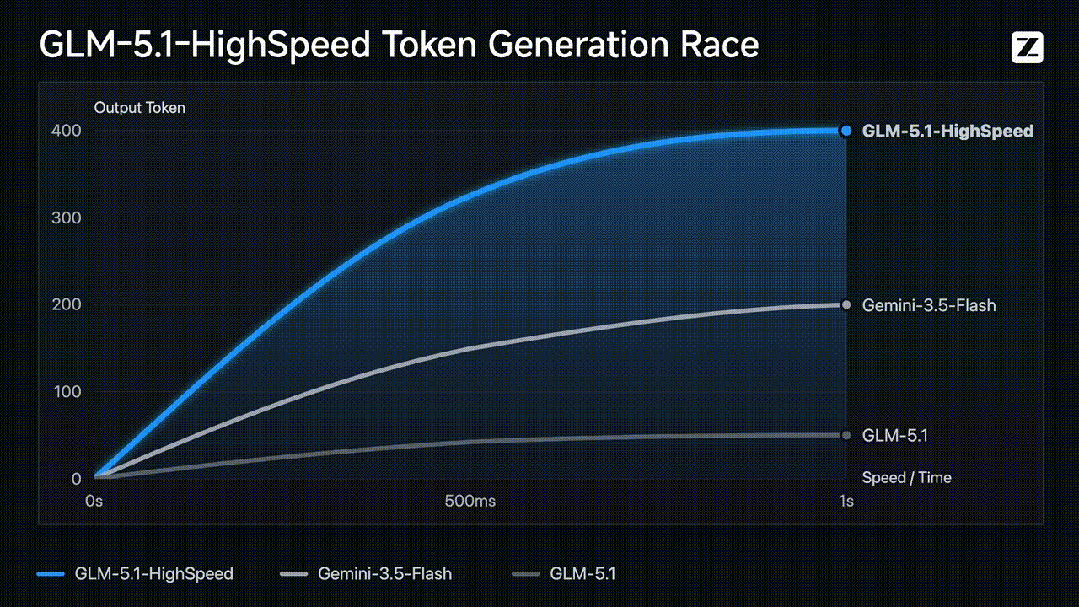
但数字本身并不可怕,可怕的是它带来的体感变化。过去我们用AI写代码,像等CPU渲图——模型一个字一个字往外蹦,你盯着屏幕干着急。现在GLM-5.1高速版像是装上了GPU,代码“啪的一下喷出来”,你刚输入需求,函数、接口与调用链已经同步展开。这种从“等待对话框”到“实时协作伙伴”的转变,才是400 tokens/s真正的价值所在。
二、实测:场景越刁钻,速度优势越明显
智谱官方和多家媒体公布了一系列实测,这里挑几个最“颠覆认知”的案例:
1. 写代码像开了10倍速
同一个复杂网页制作任务——要求生成一个包含粒子动画、音频节奏响应、可调参数的“呼吸星云”交互页面——GLM-5.1高速版在十几秒思考后,一口气喷出完整代码,包含前端结构、Canvas动画、状态管理、视觉参数和交互逻辑,且运行效果直接达标。更绝的是,你可以像跟设计师坐在一起那样,连续修改:“波纹再快一点”“光晕颜色偏暖”“粒子散开柔一点”……模型实时理解模糊指令并准确修改,整个协作过程几乎零等待。
2. 3D游戏实时建模,导演模式成真
让模型当游戏导演:玩家控制角色在3D地图移动,输入文字“下雪”“下雨”“爆炸”,场景瞬时改变。此前因延迟而无法实现的全新产品形态——例如AI实时修改游戏世界状态——现在开始具备落地可能。这已不仅仅是更快地回答问题,而是实时地创造体验。
3. Agent任务效率飞跃
在Agent Swarm场景中,GLM-5.1高速版可以瞬间调度50个不同人格来并行回答。长程任务中,每一步响应快1秒,整体任务耗时就可能缩短十几分钟。对于Coding Agent这类需要数十轮模型调用的场景,速度提升直接意味着“从不能用到好用”的质变。
三、速度背后的硬核技术:TileRT推理引擎
速度不是天上掉下来的。GLM-5.1高速版由智谱GLM团队与TileRT团队联合打造,在推理引擎、调度系统与底层基础设施三个层面做了系统性重构。
核心问题:传统推理框架以operator/kernel为基本调度单元,每个算子都要经历“host启动→读权重→计算→写回→同步”的完整链路。当进入单token、小batch、多卡TP场景后,算子被切到微秒级,调度、访存与同步开销迅速放大,导致GPU算力被大量浪费。
TileRT的答案:彻底抛弃Runtime层的动态调度,在编译期(AOT)将整个计算图静态编排为一个常驻GPU的persistent Engine Kernel。单卡内,计算、异步IO与通信全部拆解为Tile级微任务,整个推理过程只Launch一次Engine Kernel,中间结果不再写回Global Memory,而是经由Register、Shared Memory与L2 Cache直传。多卡尺度上,不同GPU rank不再执行同构逻辑,而是按计算密度与数据依赖特化为不同worker,例如GPU 0负责稀疏索引,GPU 1-7负责MLA计算。
用一句通俗的话:过去像一群工人每搬一块砖都要等工头发一次指令;现在提前把路线、分工、节奏排好,让工人持续在工地里流水线协作。这带来的不仅是峰值速度,更是真实生产环境下持续稳定的低延迟——400 TPS不是实验室的“峰值数字”,而是可用的生产级能力。
四、适用场景与未来展望
GLM-5.1高速版目前面向智谱MaaS平台部分企业客户开放,主要适用于AI编程、实时交互、商业决策、实时语音等对响应延迟要求极高的场景。可以预见,当旗舰模型能力和高速推理系统叠在一起,AI Agent的体验会出现一个直观变化:等待变少,反馈变密,任务推进更连续。
正如TileRT团队提出的论断:速度正在成为下一个Scaling Law。因为推理速度越来越直接地影响模型在固定延迟预算内能完成的推理深度、交互质量与Agent响应能力——更快意味着更多rollout、更深的推理路径、更强的自验证能力。
📚 文章来源
- 智谱官方公众号《GLM-5.1高速版:400 tokens/s,顶尖模型跑出最快速度》(2026年5月22日)
- 量子位《顶流里最快!智谱,你是在「喷」代码吧》(2026年5月22日)
- IT之家《智谱GLM-5.1高速版AI模型发布,全球最快速度400 tokens/s》(2026年5月22日)
- TileRT技术博客《Speed as the Next Scaling Law》(tilert.ai)
- CSDN博客《智谱GLM5.1重磅上线!深度测评+全维度解析》(2026年3月28日)
本文由大国Ai导航(daguoai.com)编辑整理,基于智谱官方发布及多家科技媒体实测信息撰写。转载注明出处。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...