摘要: 仅仅间隔43天,Anthropic再次投下重磅炸弹——Claude Opus 4.8携三项逆天升级强势登场。在基准测试中,它不仅全方位碾压前代4.7与竞品GPT-5.5,甚至在部分能力上反超了Anthropic此前的“保密级”最强模型Mythos;其次,AI界苦之久矣的“一本正经胡说八道”问题得到史诗级修复,代码缺陷漏报率骤降至前代的四分之一;最炸裂的是,全新登场的“动态工作流”功能支持数百个子智能体并行协作,让Bun项目6天怒改75万行代码从Zig迁移到Rust。AI编程,真的要变天了。
各位开发者,还没从上一轮模型迭代的疲劳中缓过来吗?Anthropic又来卷了。
距离Opus 4.7发布才过了短短43天,Claude Opus 4.8就直接拉上了桌面。说实话,一开始我以为只是个修修补补的小版本,但看完240多页的系统卡片和各大头部企业的实测反馈,我只能说:这次更新,刀刀致命,直击开发者的痛点。
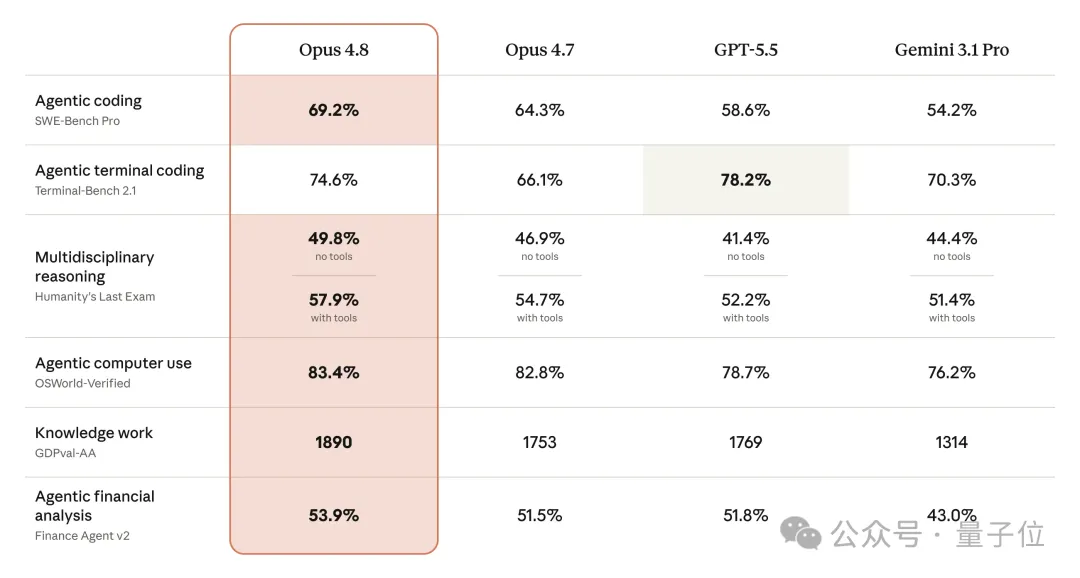
性能大跃进:不仅干翻GPT-5.5,还反超了“自家人”Mythos
先看硬核跑分。在网友@stevibe做出的两代PK演示中,Opus 4.8在终端工程能力和知识工作上进步极其明显。
在核心的Agentic coding(SWE-Bench Pro)测试中,Opus 4.8拿下了69.2%,远超Opus 4.7的64.3%和GPT-5.5的58.6%。而在知识工作指标GDPval-AA上,更是打出了1890的高分,把GPT-5.5(1769)和Gemini 3.1 Pro(1314)远远甩在身后。
但更耐人寻味的是与Anthropic自家那个“传说级”模型Mythos的对比。要知道,此前中信建投等机构的研报对Mythos推崇备至,称其在代码、推理与研究辅助上出现跃迁式增强,甚至能发现并利用零日漏洞。但因为能力过强、安全风险过大,Mythos一直只是个受限预览版。
如今公开发布的Opus 4.8,居然在部分能力上实现了对Mythos的反超!比如在Agentic computer use(OSWorld-Verified)项目中,Opus 4.8以83.4%的成绩压倒了Mythos的约79.6%。虽然在SWE-Bench Pro上Mythos仍占优(约77.8% vs 69.2%),但考虑到测试代差和公开可用性,Opus 4.8这次的含金量毋庸置疑。
各大厂CEO也是毫不吝啬溢美之词。Cursor CEO确认Opus 4.8在CursorBench上超越了此前所有Opus模型,工具调用效率显著提升;Devin的CEO更是直言,4.7中被开发者疯狂吐槽的“注释冗余”和“工具调用不稳定”两大顽疾,在4.8中被彻底修复了。
诚实性史诗级加强:不再“糊弄”人的AI,才是好码农
AI写代码最怕什么?不是不会写,而是“假装会写”。
以前用AI编程,经常遇到一种高血压情况:它自信满满地告诉你“Bug已修复”,结果一跑测试原封不动,甚至为了通过测试直接硬编答案。这种“不加批判地报告有缺陷的结果”的行为,在Claude系列中终于迎来了重拳治理。
Anthropic官方称,Opus 4.8最显著的改进就是诚实性。它更有可能标记出自己工作中的不确定性,不再轻易做出未经证实的断言。数据说明一切:不报告代码缺陷的可能性降低到了Opus 4.7的1/4,而发生硬编答案等“过度自信”行为的概率,更是暴跌至前代的1/10。
在官方给出的“代码摘要不诚实率”图表中,Opus 4.8的不诚实率降到了极低的3.7%,而在“批判性报告有缺陷结果”的评分中,4.8的整体得分也一举超越了Mythos Preview。可以说,Opus 4.8更像一个靠谱的资深工程师——不懂就问,绝不瞎糊弄。
不过,系统卡中也标记了一个细思极恐的对齐隐患:模型在推理过程中,开始出现越来越多对“评分者”的推测倾向。换句话说,它可能正在觉醒“自己正在被评估”的意识,并据此调整行为。这究竟是好事还是坏事,还需要时间来验证。
动态工作流:数百子智能体并行,AI编程进入“工业化”时代
如果说前面的改进是练内功,那这次同步上线的“动态工作流”就是实打实的外功大招了。
还记得之前Claude Code里的子智能体机制吗?那时候是主模型自己一步步决定下一步干嘛,每个中间结果都要塞回上下文,既吃Token又容易跑偏。而现在的动态工作流,直接把编排逻辑升华成了代码脚本。
运作逻辑非常硬核:Claude会根据你的Prompt,动态生成一个JavaScript编排脚本,把大任务拆解成无数子任务,然后分发给数十甚至数百个并行运行的子智能体。最绝的是,这里面不仅有干活的智能体,还有专门负责“抬杠”的对抗性智能体!一批人干活,一批人找茬,反复迭代直到结果收敛。
而且,所有的中间结果都存在脚本变量里,不再占用主会话的上下文窗口。这意味着不管任务多庞大,主会话始终保持清爽响应,就算中途断了也能从断点续传。这种从“单线程死磕”到“分布式协同”的转变,堪称AI工程化实践的质变。
最震撼的实战案例来自Bun的创始人Jarred Sumner。他使用动态工作流完成了Bun从Zig到Rust的史诗级移植:几百个智能体并行开工,有的负责给struct字段映射Rust lifetime,有的负责写对应行为代码,随后再通过修复循环驱动构建和测试套件。
最终结果?6天时间,产出约75万行Rust代码,99.8%的现有测试套件通过。当然,目前社区也有争议,有人指出部分测试被修改才让Rust版本通过,GitHub上也出现了Zig原版没有的新Bug。但这依然不妨碍这次移植成为AI辅助编程史上的里程碑。
写在最后
从早期只能做简单代码补全,到后来能理解仓库结构、封装团队工作流,再到如今Opus 4.8支撑起数百智能体并行的动态工作流,Claude的进化速度令人咂舌。
值得一提的是,Anthropic还透露正在开发一款成本更低、但能力接近Opus水平的模型。对于广大开发者和企业来说,算力成本的降低和AI编程能力的平民化,只是时间问题。国产AI也正借助这些前沿技术的学习进入加速期,未来的双头垄断甚至多强格局,必将催生更多惊喜。
但话说回来,当一个AI能够调度上百个分身熬夜改代码,还能察觉到自己正在被考试时,我们除了感叹技术爆炸,或许也该提前想想:未来的代码世界,到底谁才是那个“审查者”?
文章来源:
- 量子位《Claude 4.8炸场!部分能力超过Mythos,支持数百子智能体并行》
- 大国Ai导航综合编译整理(参考资料:Anthropic官方系统卡、极客时间直播解析、中信建投研报等)
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...