
摘要
2026年6月27日,OpenAI正式发布新一代旗舰大模型GPT-5.6系列,首次采用”太阳系”天体命名体系,推出Sol(太阳)、Terra(地球)、Luna(月亮)三款分层模型。旗舰版Sol在Terminal-Bench 2.1编程基准中以88.8%得分超越Anthropic的Claude Mythos 5(88.0%),开启Ultra模式后更是达到91.9%的新纪录。然而,由于特朗普政府6月2日签署的AI行政令要求,GPT-5.6目前仅向约20家”可信合作伙伴”开放有限预览,部分客户访问权限甚至需要美国政府逐一审批,这在AI发布史上尚属首次。OpenAI同时在公告中罕见加入措辞强硬的声明,公开表达对政府审批流程的不满。
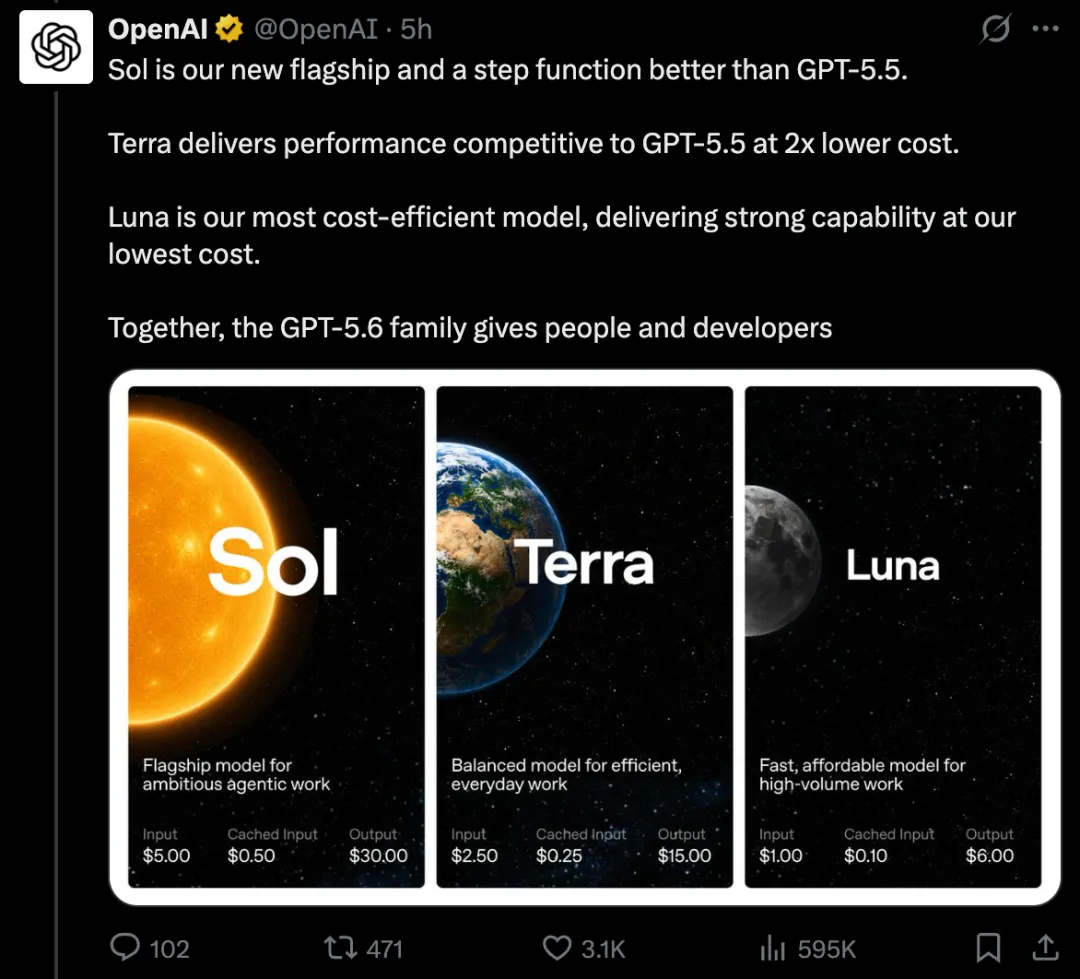
一、全新命名体系:从Pro/Mini到”太阳系”宇宙
从GPT-5.6开始,OpenAI彻底抛弃了过往的Pro、Mini、Instant命名方式,转而采用天文学概念构建全新的模型矩阵。
- GPT-5.6 Sol(太阳):旗舰型号,定位最复杂推理、科研、软件开发、网络安全、生物研究以及AI Agent工作流。
- GPT-5.6 Terra(地球):均衡型,主打综合能力,性能接近GPT-5.5的同时成本降低约50%。
- GPT-5.6 Luna(月亮):速度最快、价格最低的轻量版,适合大规模在线服务及高吞吐场景。
这种”数字代际+能力层级”的双维度命名框架,让开发者可以在智力水平、速度与成本之间做出最清晰的选择。值得注意的是,Sol、Terra、Luna这三个名字与加密项目Solana(SOL)、Terra(LUNA)名称重合,引发了加密社区热议,但OpenAI明确表示该系列模型与上述加密资产无任何直接关联。
二、性能全面突破:编程、网安、生物三大领域刷新纪录
1. 编程能力:Terminal-Bench 2.1 创下新SOTA
在检验编程工作流的Terminal-Bench 2.1测试中,GPT-5.6 Sol表现抢眼:
| 模型 | Terminal-Bench 2.1 得分 |
|---|---|
| GPT-5.6 Sol Ultra | 91.9% |
| GPT-5.6 Sol | 88.8% |
| GPT-5.5 | 88.0% |
| Claude Mythos 5 | 84.3% |
| Claude Fable 5 | 83.4% |
| GPT-5.6 Luna | 84.3% |
| GPT-5.6 Terra | 82.5% |
| Claude Opus 4.8 | 78.9% |
| Gemini 3.1 Pro Preview | 70.7% |
Sol标准模式下得分88.8%,超过Claude Mythos 5(88.0%),开启Ultra模式后更是达到91.9%,创下新的技术水平纪录。Terra的表现与Mythos的首个公开发布版本Fable 5持平,而轻量化的Luna甚至比Anthropic目前仍能公开提供的旗舰模型Opus 4.8更强。
2. 网络安全:1/3的token达到同等水平
在ExploitBench测试中,Sol与Anthropic未公开的Mythos Preview版本表现相当,但仅使用了约三分之一的输出token,显著降低了成本。从数据来看,Sol在输出约120K token时得分大约70%,而Mythos Preview要达到相近分数需要用到三倍左右的token量。
此外,在ExploitGym(由加州大学伯克利分校研究人员与OpenAI等前沿实验室合作创建的网络基准测试)中,Sol、Terra和Luna三款模型都显示出随着推理时间增加,网络能力持续提升的趋势。
3. 生物学:GeneBench v1效率与精度同步提升
在生物学GeneBench v1测试中(评估长期基因组学和定量生物学分析能力),Sol使用比GPT-5.5更少的输出token,却拿到了更高的分数。这意味着它在给出更精准答案的同时,消耗的计算资源反而更少了。对于实验室、企业研发团队和生物医药场景来说,tokens消耗直接影响调用成本,这一改进尤为关键。
此外,据开发者披露,GPT-5.6的上下文窗口从100万tokens扩展至150万tokens,提升约43%,能够一次性处理整个代码库或数本书籍的内容。在长链条Agent任务上,token消耗据称比GPT-5.5再节省10%至15%。
三、两种高阶推理模式:Max与Ultra
GPT-5.6 Sol引入了两种全新的推理控制模式:
- Max Reasoning(最大推理强度):让模型在困难问题上花更多时间深度推理,类似于把思维链拉到极限。
- Ultra模式:更激进的配置,引入”子代理”机制,可以把一个复杂任务拆分给多个Agent并行处理,而不是一个模型一路问到底。
这两个功能都会增加延迟和成本,换来的是准确率的提升,尤其在需要长时间规划的编码和安全研究场景。在真实开发场景里,模型经常需要理解项目结构、读取文件、修改代码、运行命令、分析报错、继续修改,Ultra模式让多个子Agent分别处理不同环节,再把结果汇总起来,从而提高复杂任务的完成效率。
四、定价策略:旗舰不涨价,Terra直接腰斩
OpenAI这次给GPT-5.6的定价呈现出明显梯度差异:
| 模型 | 输入价格(每百万token) | 输出价格(每百万token) |
|---|---|---|
| GPT-5.6 Sol | $5 | $30 |
| GPT-5.6 Terra | $2.5 | $15 |
| GPT-5.6 Luna | $1 | $6 |
值得注意的是,GPT-5.6 Sol虽然是新一代旗舰模型,但价格对齐的是GPT-5.5标准版,而不是GPT-5.5 Pro。Terra则直接降到GPT-5.5的一半,Luna只有GPT-5.5的五分之一。Sol的定价仅为Anthropic Claude Fable 5(10美元/50美元)的一半左右。
横向对比来看,Claude Mythos Preview(受邀内测)为输入25美元、输出125美元,是Sol的5倍以上。智谱的GLM-5.2(MIT开源)输入1.4美元、输出4.4美元,和Luna处在同一价格带,但Luna是闭源模型,按理说应该有能力溢价——OpenAI显然在用Luna守住低价市场,不让开源模型和中国厂商吃掉这块。
GPT-5.6还引入了更可预测的提示词缓存机制,包括支持显式缓存断点和至少30分钟的缓存生存期。对于GPT-5.6及更高版本模型,缓存写入按模型未缓存输入费率的1.25倍计费,而缓存读取继续享受90%的缓存输入折扣。对于大量重复上下文的企业场景,这能进一步压低实际使用成本。
五、Cerebras合作:7月上线750 token/s恐怖速度
OpenAI宣布与Cerebras达成合作,7月份将在Cerebras晶圆级推理芯片上运行GPT-5.6 Sol,目标实现每秒高达750个Token的生成速度。这一速度较当前主流旗舰模型快近一个数量级。首批权限同样将限制在部分客户群体中,随后逐步扩大产能。如果这个数字属实,意味着用旗舰模型也能获得接近实时的响应体验。
六、美国政府”一客一审”:AI发布史上首次
相比模型性能,更受市场关注的是此次的发布方式。
OpenAI在公告中披露,在发布之前已向美国政府展示了计划及模型能力,”应政府要求”,将首先向一小部分”可信合作伙伴”提供有限预览,这些合作伙伴的参与情况已向政府报备。据报道,首批获得权限的企业约二十家左右。
更令人关注的是审批方式——部分客户的模型访问权限甚至需要美国政府逐一批准。OpenAI CEO山姆·奥特曼在内部备忘录中明确写道,在GPT-5.6的预览期内,客户将被逐一审批访问权限,这在AI发布史上尚属首次。
这一安排源于特朗普政府6月2日签署的AI行政令,该命令建立了针对前沿AI模型的安全评估框架,允许政府在模型发布前至多30天获取访问权限进行审查。虽然行政令强调参与”自愿”,但实际操作中已演变为事实上的强制审批。此前,Anthropic的Fable 5发布仅3天便被要求下线,原因是收到美国政府出口管制指令,禁止一切外国国民(含Anthropic外籍员工)访问Fable 5与Mythos模型。
七、OpenAI罕见公开表达不满
虽然配合了政府要求,但OpenAI在公告中罕见加入了措辞强硬的声明:
“我们不认为这种政府访问审批流程应成为长期默认做法。它剥夺了需要这些最佳工具的用户、开发者、企业、网络防御者和全球合作伙伴的使用权。”
公司表示,目前的限量预览是”短期措施”,是未来几周实现更广泛开放的最有力路径。OpenAI计划未来与政府合作制定网络安全行政令框架,以及可重复执行的模型发布流程。
八、安全防护体系:分层防护但未触及”Critical”
GPT-5.6系列采用分层防护体系:
- 模型内置拒答(包括对越狱尝试的拒绝)
- 生成过程实时分类器(网络安全和生物学滥用分类器)
- 账户级风险审查(跨对话的持续滥用vs合法双重用途工作)
- 差异化访问、监控和执法机制
- 对于高风险情况,系统可暂停生成并交由更大推理模型复核
OpenAI特别强调,GPT-5.6被训练为会拒绝提供被禁止的网络安全协助。即便这一层防护被恶意行为者通过不断尝试提示词绕过,实时网络安全和生物学滥用分类器也会在模型生成输出的过程中进行评估,并对潜在恶意行为进行拦截。
OpenAI在系统安全卡中披露,GPT-5.6全系列三个模型都被内部评为”High”风险等级(网络安全和生化能力维度),但没有触及最高的”Critical”级别。 Preparedness Framework评估显示,Sol在Chromium/Firefox测试条件下未跨越Cyber Critical门槛——即在所述条件下无法自主完成全链漏洞利用。
OpenAI的定位是:Sol更擅长帮助防御者发现和修复漏洞,而非可靠执行端到端攻击。这一框架呼应了华盛顿对Mythos级别模型的担忧,同时为”带防护的防御者访问”提供了论据。据披露,OpenAI在自动化红队测试(针对通用越狱)上消耗了70万+ A100等效GPU小时,预览期间还将持续进行第三方人工红队测试。
九、开发者评价:升级幅度远超5.4到5.5
已经测试了GPT-5.6一段时间的开发者swyx评价道:
“千万不要把它仅仅视为一个’网络’版本,它是新的SOTA工作马模型,完全取代了我80%任务中的opus。GPT-5.6 Sol使用仅约1/3的输出令牌,就与Mythos Preview具有竞争力。OAI后训练团队大幅推进了推理帕累托前沿……我真心希望他们干脆直接叫它GPT6,因为这个小小的语义版本号升级,其改进幅度甚至远远超过5.4到5.5的跳跃。”
十、总结:性能新高+政治博弈的双重重磅
GPT-5.6的发布是OpenAI在两个维度上的重磅事件:
技术维度:Sol在编程、网络安全、生物学三大领域全面刷新SOTA,Ultra模式的子Agent协同机制开创了新的能力上限,150万token上下文窗口和Cerebras 750 token/s的推理速度,让它在长链条Agent任务和实时交互场景中具备压倒性优势。
政治维度:美国政府”一客一审”的审批机制,标志着前沿AI模型已经从单纯的技术产品,转变为涉及国家安全的战略资源。Anthropic的Fable 5被迫下线、OpenAI的限量预览,都表明AI监管已经从”自愿框架”演变为事实上的强制审批。
对开发者而言,GPT-5.6的定价策略(旗舰不涨价、Terra腰斩、Luna守住低价)显示出OpenAI在性能领先的同时,也在用价格武器巩固市场份额。但政府审查带来的不确定性,可能成为未来AI行业发展的最大变量。
文章来源:综合TechWeb、智东西、IT之家、钛媒体、21世纪经济报道、新浪财经、品玩、explainx.ai等多家媒体报道整理。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...