【摘要】
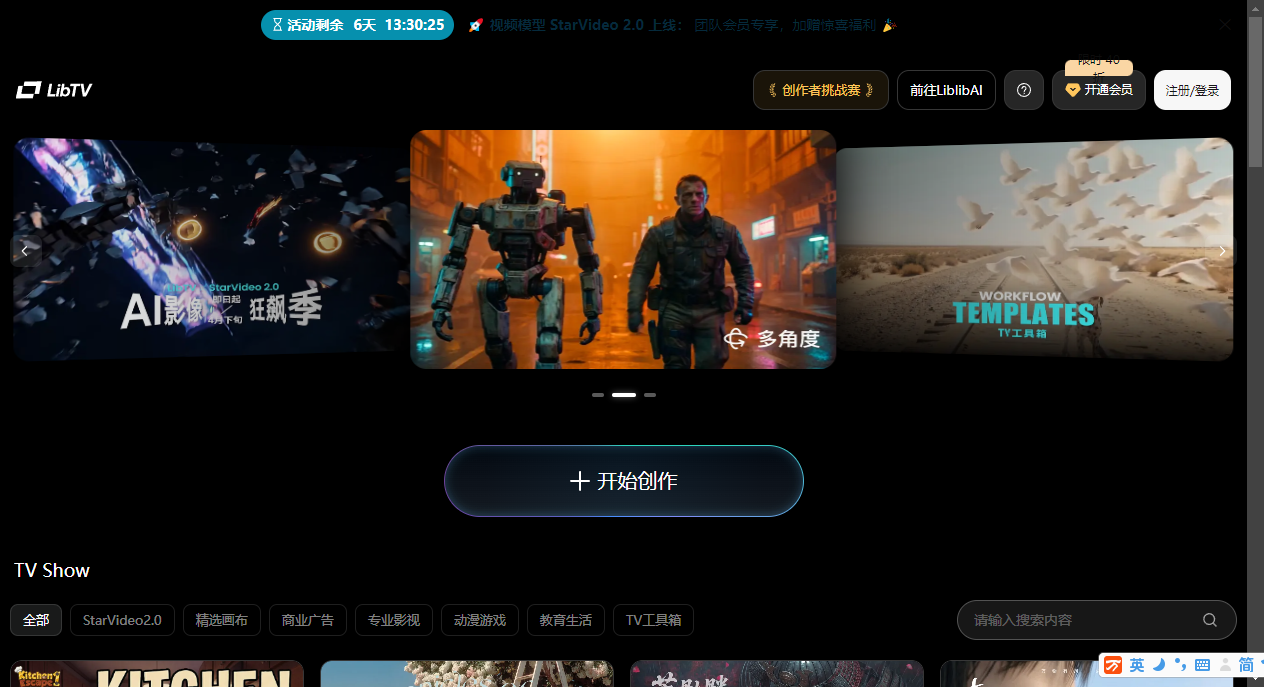
LibTV 是 LiblibAI 推出的一站式 AI 视频创作平台,采用“无限画布 + 节点式工作流”,将剧本、分镜、镜头、剪辑等环节在同一空间内结构化组织,支持从脚本、分镜到成片的完整流程。产品首创“人类创作者 + AI Agent 双入口”结构:人类在画布上搭建和调整工作流,Agent 通过 Skill 接口实现从一句话需求到成片的自动化生产,已集成可灵 3.0、Wan 2.6、Seedream 5.0、Midjourney V7 等多模态模型以及 Mureka 音频生成模型,上线首日访问量突破 10 万。整体设计更接近影视制作流程,而非传统单点 AI 视频生成工具。
【官网入口】
一、定义与定位:从“生成工具”到“创作系统”
LibTV 定位为“同时面向人类创作者与 AI Agent 的专业视频创作平台”,核心不是单一模型能力,而是通过产品结构重构创作流程。
- 一站式 AI 视频创作平台:将剧本生成、分镜设计、图像生成、视频生成、音频生成、后期剪辑等环节整合在同一平台内,避免在不同工具间反复切换。
- 无限画布 + 节点式工作流:以无限大的画布承载项目,用户可创建文本、图片、视频、音频、脚本五种基础节点,并通过连线组织数据流,使视频创作从线性操作转为结构化流程。
- 人类创作者 + AI Agent 双入口:传统图形界面面向人类用户,同时提供面向 AI Agent 的 Skill 接口,让 OpenClaw 等“龙虾”类 Agent 可直接调度视频生产能力,实现“一句话出片”。
- 多模态模型集成:平台已集成可灵 3.0、Wan 2.6、Seedream 5.0、Midjourney V7 等图像/视频模型,以及 Mureka 等音频生成模型,覆盖文本、图像、视频与音频生成。
简单理解:LibTV 把传统影视制作流程“搬到”一块画布上,并把这套能力同时封装给人类和 Agent 使用。
二、核心功能与技术特点
2.1 创作结构与工作流能力
三、如何使用 LibTV
3.1 人类创作者使用流程
- 注册与登录
访问官网 https://www.liblib.tv,使用手机号或第三方账号登录,即可进入项目列表。
- 创建项目与画布
在“最新项目”中点击“开始创作”,进入无限画布界面。双击空白处即可创建节点,或直接拖入本地素材。
- 从文本 / 脚本开始
- 创建“脚本”节点,输入故事大纲或分镜提示词,平台自动生成详细分镜脚本,包含时长、画面描述、景别、动作、情绪、光影氛围等字段。
- 可选择“剧本生成分镜脚本”“视频参考生成分镜脚本”“角色生成分镜脚本”等多种模式。
- 生成分镜图与视频
- 点击“生成分镜”,系统批量生成多张分镜图。
- 再点击“批量生成视频”,将静态分镜转为动态视频片段。
- 专业工具与后期
- 选中图片或视频节点,使用“/”调出专业工具,如电影级灯光校正、多机位九宫格、25 宫格连贯分镜、多角度/摄像机控制等。
- 在画布内完成裁剪、拼接、高清处理等操作,减少对外部剪辑软件的依赖。
- 工作流复用与模板
将常用节点组合保存为工作流模板,后续只需更换输入素材,即可一键生成同风格系列视频。
3.2 Agent(龙虾 / OpenClaw)使用流程
- 准备 OpenClaw 环境
可选择本地版或飞书插件版 OpenClaw,按官方文档完成部署。
- 安装 LibTV Skill
- 获取 Access Key
登录 LibTV 官网,鼠标移到右上角头像,复制 Access Key,在 OpenClaw 中配置为环境变量 LIBTV_ACCESS_KEY。
- 在 IM 中一句话生成视频
在飞书 / 钉钉 / 企业微信中与机器人对话,例如:“生成一个 60 秒的漫剧,讲述《守株待兔》的摸鱼员工…”,Agent 会自动完成剧本生成、分镜设计、视频生成和合成导出。
- 回到画布精细调整
Agent 生成的项目会同步到 LibTV 后台,用户可在画布中继续调整分镜、镜头与剪辑,实现“IM 快速出片 + 画布精细打磨”的闭环。
四、适用人群与场景
- 专业影视创作者:利用节点工作流、角色三视图、电影级灯光控制、多机位宫格等功能,提升从脚本到成片的整体效率,适合短片、MV、广告片、短剧等制作。
- 内容运营 / 电商团队:搭建固定工作流模板后,批量产出产品广告、短视频内容,保持风格统一,降低重复制作成本。
- Agent 用户 / 个人开发者:通过 Skill 接口让龙虾等 Agent 自动化完成视频任务,适合想“少操作、多创意”的个人创作者或自动化工作流爱好者。
- AI 视频入门者:无需精通多个工具,即可在单一画布内完成从文本到视频的全流程,上手门槛较低。
关键词:LibTV · LiblibAI · AI 视频创作平台 · Agent 视频工作流 · 节点式创作系统
【文章来源】
本文基于公开报道与实测资料整理,主要信息来源包括南方+、腾讯新闻、人人都是产品经理等对 LibTV 的官方报道与实测文章。
【版权说明】
本文由大国 AI 导航(daguoai.com)整理撰写,仅供学习与交流使用,不构成任何投资或法律建议。如需转载,请注明出处并保留本段声明。如需商业使用或对内容有异议,请联系官方渠道处理。