
摘要:2026年1月13日,中国AI公司百川智能正式开源新一代医疗大模型Baichuan-M3。该模型在全球权威医疗AI评测HealthBench及其复杂决策子集HealthBench Hard上双双夺冠,综合得分65.1分,首次在医疗领域全面超越OpenAI的GPT-5.2。更为关键的是,M3实现了3.5%的全球最低医疗幻觉率,并首次具备了原生的“端到端严肃问诊”能力,其问诊水平在SCAN-bench评测中显著超越人类医生基线。这标志着中国AI医疗技术从“跟随”迈入“引领”阶段,为安全、可靠的规模化医疗AI应用奠定了基石。
一、 登顶全球:医疗沟通与推理能力超越GPT-5.2
今日,百川智能的开源公告在AI与医疗交叉领域投下了一枚“重磅炸弹”。其发布的Baichuan-M3模型在全球最权威的医疗AI评测集HealthBench中,以65.1分的综合成绩位列第一;在专门考验复杂临床决策能力的HealthBench Hard上,更以44.4分的成绩夺冠。这一成绩不仅刷新了该评测的最高分记录,更实现了对国际巨头OpenAI最新模型GPT-5.2的全面超越。
这一超越并非一蹴而就。回溯至2025年8月,百川开源的上一代医疗模型M2已在HealthBench上力压同期所有开源模型,并在Hard子集上成为全球唯二突破32分的模型,仅次于当时的GPT-5。在随后的五个月里,百川团队对其强化学习系统进行了“全面升级”,将半动态反馈体系演进为全动态Verifier System。随着监督信号持续变细、变难,模型能力不断突破上限,最终使M3在复杂医学问题的表现上实现“跃迁”,登顶全球医疗沟通与推理能力最强模型的宝座。
二、 攻克“拦路虎”:重构训练范式,刷新全球最低幻觉率
对于志在进入严肃医疗场景的AI而言,“幻觉”(即模型生成不准确或虚构信息)是必须攻克的核心安全难题。百川智能创始人王小川在发布中指出,在大多数场景幻觉仅是体验问题,但在严肃医疗中可能导致安全事件。
百川M3的创新在于将幻觉抑制“前移”至模型训练阶段。团队在强化学习过程中,将医学事实一致性作为核心训练目标之一,把“知之为知之,不知为不知”的理念直接作用于模型自身能力的形成过程。这一方法将医学事实可靠性内化为M3的基础能力,使其在不依赖任何外部检索系统的情况下,也能基于自身知识进行稳定、可信的作答。
成果是显著的:通过重构幻觉抑制的训练范式,M3在纯模型设置下实现了3.5%的医疗幻觉率,超越了以低幻觉著称的GPT-5.2,达到全球最低水平。这为AI在诊断辅助、患者咨询等高风险场景中的可靠应用扫清了关键障碍。
三、 定义新范式:“严肃问诊”实现端到端能力突破,超越人类医生
如果说超越GPT-5.2展现了M3的“硬实力”,那么其首创的“严肃问诊”能力则定义了AI医疗应用的“新范式”。长期以来,通过Prompt让模型“角色扮演”医生是常见做法,但这只能激活模型的表演行为,而非内生的、以安全为核心的临床思维。
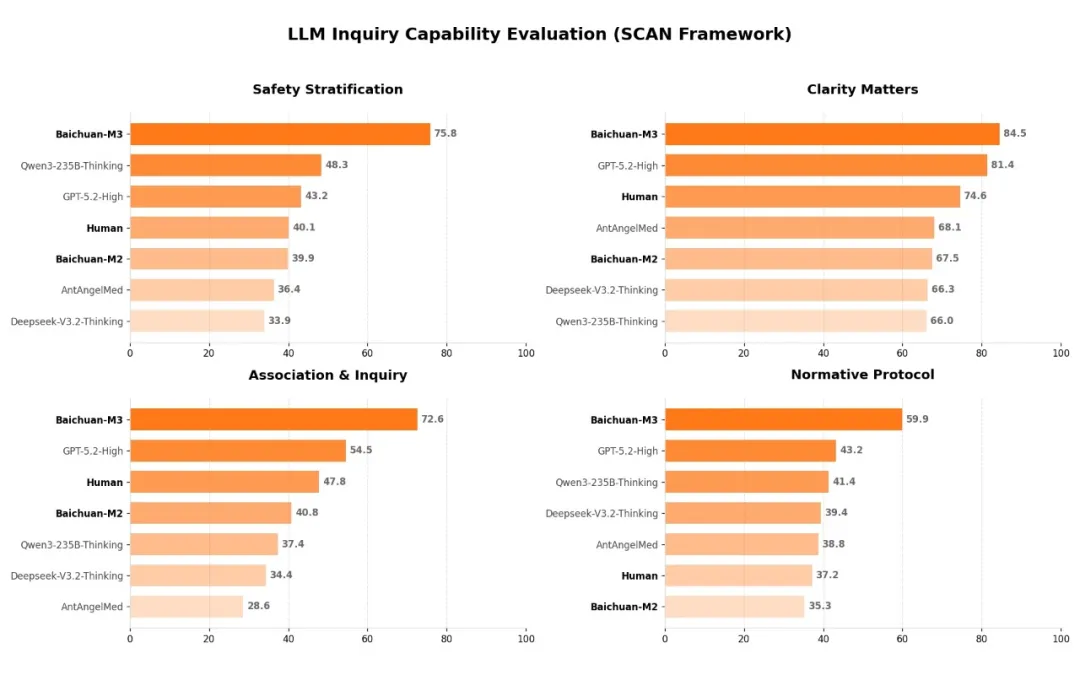
针对这一行业困境,百川提出了“严肃问诊范式”与 “SCAN原则” ,即:
- Safety Stratification(安全分层):优先识别与处置危急重症。
- Clarity Matters(信息澄清):确保关键病史清晰无误。
- Association & Inquiry(关联追问):像医生一样主动、深入地追问。
- Normative Protocol(规范化输出):使输出经得起临床复核。
为了系统化地训练与评估这一能力,百川联合150多位一线医生,借鉴医学教育中的OSCE方法,搭建了SCAN-bench评测体系。该体系以真实临床经验为“标准答案”,动态、多轮地考核从病史采集到精准诊断的全过程。评测结果显示,M3在SCAN的四个维度上均显著高于人类医生基线水平,并大幅领先国内外其他顶尖模型。
此外,团队还设计了新的SPAR算法,以解决长对话训练的稳定性问题,使模型能在有限轮次中问准、问全关键问题。实验揭示了一个重要规律:问诊准确度每提升2%,诊疗结果准确度就会增加1%。这证明了提升问诊质量对于最终诊疗安全的决定性作用。
四、 应用落地与行业意义:从技术引领到生态构建
随着M3的发布,百川智能的医疗应用“百小应”已同步接入新模型,面向医生与患者开放。医生可借助它推演问诊与诊疗思路,患者及家属则可更系统地理解诊断、治疗背后的医学逻辑。
此次发布正值全球AI医疗竞争进入“深水区”。从OpenAI发布ChatGPT Health,到Anthropic推出Claude for Healthcare,国际巨头纷纷加码。百川智能作为国内唯一专注医疗大模型的企业,通过持续突破低幻觉、端到端问诊和复杂临床推理等核心能力,已从“跟随者”跃迁为行业“引领者”与新范式的“定义者”。
百川智能创始人兼CEO王小川同日透露,公司预计将于2027年启动IPO上市。结合近期港交所迎来多家AI企业上市的热潮,资本市场对硬核AI技术的认可度正持续升温。Baichuan-M3的开源,不仅以硬核实力扛起了中国AI医疗发展的旗帜,更可能为整个行业的技术演进与安全标准树立新的标杆。
文章来源:综合自百川智能官方发布、TechWeb、猎云网、科创板日报、观点网及ITBear科技资讯等媒体报道,由大国AI导航(daguoai.com)整合改写。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...