摘要: 2026年6月22日,日本AI独角兽Sakana AI发布多智能体编排系统Fugu及Fugu Ultra,以仅7B参数的核心模型通过动态调度GPT-5.5、Gemini 3.1 Pro、Claude Opus 4.8等顶尖大模型,在工程、科学推理等多项基准测试中性能对标甚至超越Anthropic的Fable 5和Mythos Preview。这一突破打破了”参数即正义”的迷思,也为算力受限地区提供了一条AI突围新路径——不再拼单体大模型,而是拼模型组织能力。本文深度解读Fugu的技术架构、性能表现、商业逻辑及对AI行业格局的启示。
一、Sakana AI:日本AI独角兽的自然启发式路线
要理解Fugu为何能”叫板”Fable 5,先得认识Sakana AI这家公司。
Sakana AI成立于2023年,总部位于东京,由Transformer论文《Attention Is All You Need》的共同作者Llion Jones、前Google Brain日本研究团队负责人David Ha,以及拥有日本外务省、Mercari和Stability AI背景的Ren Iito联合创办。
“Sakana”在日语中是”鱼”的意思,这家公司的logo并非装饰,而是其技术路线的隐喻——单条鱼不强,但鱼群会形成整体智能;单个模型未必万能,多模型协作可能才是下一层入口。2025年,Sakana AI获得NVIDIA、Google等巨头投资,估值超过25亿美元。
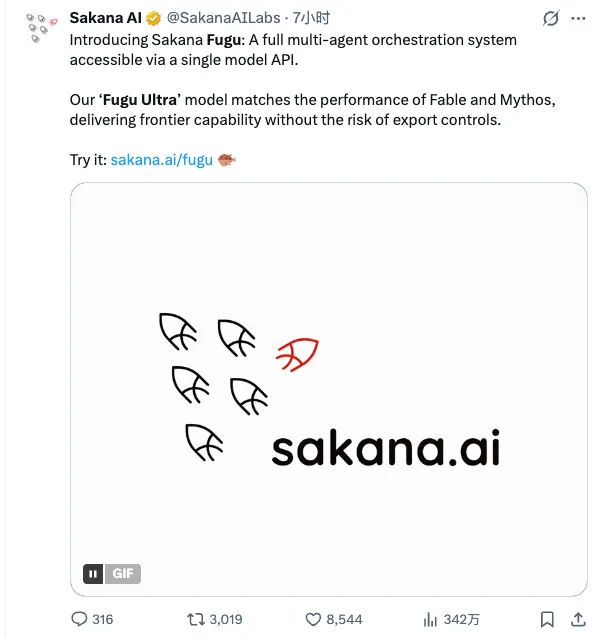
从诞生之初,Sakana AI就带着鲜明的”自然启发式”基因,致力于用进化算法和自然界的群体智能来解决AI问题。即便有巨头背书,日本本土依然缺乏中美那样庞大的算力基础设施和数据池。在这种资源约束下,Sakana AI没有选择硬刚千亿参数大模型,而是走了一条”编排”路线。
这次发布的Fugu,正是Sakana AI过去两年研究路线的一次产品化:把”很多智能体如何协作”从论文和demo,推到一个能收费、能接入企业工作流的API里。
二、Fugu的技术架构:7B参数的”包工头”
反常识的编排模型设计
传统大语言模型是一个”单体巨兽”——用户输入提示词,模型从第一层神经网络计算到最后一层输出结果。这种模式处理简单问题效率极高,但面对复杂多步骤工程任务时,往往出现幻觉或逻辑断裂。
Fugu彻底改变了这一范式。它的核心是一个经过强化学习训练的7B参数模型,被称为RL Conductor。这个7B模型本身并不直接生成最终答案,而是扮演”包工头”的角色。
当用户通过单一OpenAI兼容API提交任务后,RL Conductor会动态分析任务类型,然后将子任务分配给智能体池中的全球顶尖模型,比如GPT-5、Gemini 3.1 Pro或Claude Opus 4.8。它负责调度、验证和合成这些模型的输出,最终给出一个经过多重校验的结果。
TRINITY与Conductor:调度层的学术基础
Fugu背后是Sakana AI在ICLR 2026上发表的两篇论文——Trinity和Conductor。
TRINITY让coordinator给多个模型分配Thinker、Worker、Verifier角色;Conductor则用强化学习学习自然语言协调策略。换句话说,Sakana在训练的不是某一个员工,而是一个会派活的主管。
Conductor的一个亮点功能是递归测试时扩展——允许Conductor选择自己作为worker,读取自己团队之前的输出,如果发现失败就动态启动纠错工作流。这为推理阶段的计算扩展开辟了新维度。
动态角色分工的实际运作
性能突破源于系统底层的动态角色分工。例如在常识问答中,Fugu Ultra会调度Gemini-3.1-Pro担任聚合器,并由GPT-5.5与第二台Gemini作叶节点各自解题;在数学计算中则切换GPT-5.5作聚合器以纠正Gemini与Opus的计算分歧。在多轮编码任务中,Fugu Ultra会交替让GPT-5.5负责编写代码,并调度Claude-Opus-4.8承担安全审计与调试。
模型之间这种细粒度的动态互补,使系统整体表现大幅超越单个智能体。
三、Benchmark硬核对决:Fugu Ultra凭什么和Fable 5坐一桌
Sakana AI在官方公告中宣称,Fugu Ultra在行业最严苛的工程、科学和推理基准测试中,与Anthropic的Fable 5和Mythos Preview并肩而立。
核心评测成绩
| 基准测试 | Fugu Ultra | Fable 5 | 对比 |
|---|---|---|---|
| TerminalBench 2.1 | 82.1 | 80.4 | 领先 |
| LiveCodeBench | 93.2 | 89.8 | 领先 |
| GPQA Diamond | 95.5 | – | 公开可用模型最高 |
| SWEBench Pro | 73.7 | – | 超过Opus 4.8(69.2)和GPT-5.5(58.6) |
| Humanity’s Last Exam | 50.0 | 53.3 | 仅差3.3分 |
值得注意的是,Fugu Ultra的底层模型池并不包含Claude Fable 5和Claude Mythos Preview——这两个模型受出口管制,并非公开可访问模型。Fugu纯粹通过编排GPT-5.5、Gemini-3.1-Pro和Claude-Opus-4.8等公开模型,以集体智能实现了超越单一顶尖模型的越级性能。
六大实战案例验证
除了基准测试,Sakana AI还展示了六个实战案例,Fugu在AutoResearch(自动化ML研究)、魔方求解、机械设计、日文古籍识别、单次国际象棋、金融时间序列预测中,均超过Gemini 3.1 Pro、Claude Opus 4.8和GPT-5.5:
- AutoResearch:自主运行123次实验,拿到最优BPB得分0.9774±0.0019
- 日文古籍识别:处理日本历史文献阅读顺序恢复时达到NED 0.80,其他模型只有0.24或直接失败
- 魔方求解:仅用19步解开魔方,是四款模型中步数最短
- CAD机械设计:设计出可工作的虹膜机构,其他模型产出存在间隙或不完整
- 国际象棋:连续四局对弈保持完美准确率
- 股票交易:50周回测实现19.43%平均回报,其他模型均低于15%
四、AI主权与单一供应商风险:Fugu的地缘政治意义
Fugu的推出,除了技术突破,还直指一个现实问题——鸡蛋不能放在一个篮子里。
前阵子Anthropic的Claude Fable 5刚发布就被限制使用,这一事件让单一供应商依赖的风险变得无比真实。Sakana AI指出,监管框架、出口管制和各国政策的变化,可能让企业对AI模型的访问权限”一夜之间改变甚至断绝”。
对于一个组织乃至一个国家而言,将关键基础设施、金融或治理系统寄托于一家公司的API,是”现实存在的弱点”。而Fugu的设计恰恰回应了这一问题——它底层的Agent池完全可替换。如果某家供应商限制访问,Fugu可以动态绕开干扰。
Sakana AI称之为**”AI主权的现实蓝图”**。这种编排不仅是技术上的进步,更是地缘政治的产物。集体智能成为对抗权力集中的实用对冲手段。
五、商业模式与定价:调度层的价值捕获
定价策略
Sakana AI提供订阅制和按量计费两种方式:
订阅制:
- Standard套餐:月费20美元(轻度日常使用)
- Pro套餐:月费100美元(10倍Standard使用量)
- Max套餐:月费200美元(20倍Standard使用量)
按量付费模式(Fugu Ultra):
- 输入:每百万tokens 5美元(超过27.2万tokens后为10美元)
- 输出:每百万tokens 30美元(超过27.2万tokens后为45美元)
作为对比,Opus 4.8的价格是输入每百万tokens 15美元,输出每百万tokens 75美元。Fugu Ultra的输入价格只有Opus的三分之一,输出价格不到一半。
关键创新:不叠加模型费用
Fugu Ultra的定价有一个关键创新——当多个agent同时工作时,Sakana不逐个叠加模型费用,而是按参与池里最高tier的模型收一个价格。这解决了多模型系统过去”太难算账”的痛点。
Fugu把复杂性收走,再向用户收调度费。这本质上是在训练的不是某一个员工,而是一个会派活的主管——而主管的价值,正在于知道谁适合干什么。
六、行业启示:大模型战争进入”调度层”新维度
从”谁更强”到”谁能组织”
过去两年,模型公司都在抢一个位置:最强单模型。现在这个位置越来越拥挤。同一个模型,写代码强,长文本可能一般;推理强,延迟可能高;便宜模型适合日常对话,复杂agent任务又容易半路掉链子。
企业真正要买的,也不是某个榜单上的第一名,而是一次任务能不能在成本、速度、合规和稳定性之间跑完。这就是Fugu瞄准的方向。
价值分配的重构
如果底层模型越来越多,模型本身会更像可替换零件。不是不值钱,而是客户关系、工作流入口和任务数据,会逐渐往调度层集中。
谁掌握调度层,谁就知道用户在做什么任务、哪些模型在什么场景更可靠、成本卡在哪里、失败通常发生在哪一步。这比一次回答更有价值。
云计算历史的重演
云计算早期也发生过类似变化。一开始,大家关心服务器配置、机房、网络、扩容方式。后来云厂商把这些复杂性封装成服务,用户只关心应用能不能稳定跑起来。模型也在走到这一步。
调用一个模型只是开始。复杂任务里,更难的是把任务拆开、选模型、控制token、处理失败、复核结果、记录成本,再把这一切藏在一个稳定接口后面。普通router只是在模型之间分流,Fugu想做的更接近一个调度系统。
七、风险与挑战:调度层的隐忧
调度层也有自己的风险。Fugu不公开具体用了哪些底层模型,也不公开怎么协调。Fugu Ultra的模型池固定,普通Fugu可以按隐私、数据和合规要求排除某些模型或提供商。
用户得到的是更简单的入口,也交出了更多不可见的控制权。过去,你至少知道自己在用GPT、Claude或Gemini。现在,你信的是一个黑盒调度器。
四个关键观察变量
接下来要看的不是Fugu有没有某一个benchmark第一,而是四个更实际的变量:
- 复杂任务里的端到端延迟能否接受
- 调度后的成功率是否稳定高过单模型
- 新的公开frontier model出现后,Sakana能否真的在两周左右完成接入和评估
- 企业是否愿意为更好的结果,接受一个不完全透明的模型入口
Sakana在FAQ里提到:新公开frontier model发布后,他们预计花大约两周训练和评估新版Fugu,再逐步推出。这说明Fugu的目标不是绑定某个模型,而是持续吸收新的强模型。强模型越多,调度层越有用。
八、结语:编排模型——AI发展的新前沿
Sakana AI在博客中明确提出:编排模型将会超越传统大模型成为新的前沿方向。
过去几年AI进步靠暴力堆算力和数据,但现实复杂任务需要的专业知识远超单一模型的能力边界。充分发挥模型的最佳性能需要集体智慧——需要知道何时该用哪个模型、什么时候委派、怎么组合擅长不同领域的模型。
在”越大越好”的竞赛之外,Sakana AI提供了一条不同的思路:与其造一个全能的神,不如建一个懂得调兵遣将的指挥官。
大模型战争没有从”谁更强”结束。它只是进入了下一层:当强模型越来越多,谁能把它们变成一个可用系统。Fugu的发布,或许正是这场战争新阶段的发令枪。
文章来源:
- AI PIONEER《刚刚日本AI公司发布Fugu,凭什么和Fable坐一桌?》
- Sakana AI官方博客(sakana.ai/fugu-release)
- 智东西《又一大模型发布!号称比肩Fable 5和Mythos》
- Panewslab《日本AI黑马Fugu杀出:7B小模型如何叫板Fable与Mythos?》
- The Block Beats《Sakana AI发布多智能体系统Fugu,多项推理与编程评测击败Fable 5》
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...