
摘要: 2026年6月26日,OpenAI正式发布GPT-5.6系列大语言模型,首次采用天文命名体系推出Sol(旗舰)、Terra(均衡)、Luna(轻量)三款产品,构建起清晰的能力-成本分层架构。旗舰模型Sol在Terminal-Bench 2.1编程基准测试中以91.9%的得分超越Anthropic Claude Mythos 5的88.0%;Terra性能接近GPT-5.5但价格减半,Luna定位最低成本入口。新增的Ultra模式通过多子Agent并行协作处理复杂任务,Max推理模式允许更深度思考;上下文窗口从100万tokens扩展至150万tokens。受美国政府安全审查要求,目前仅向约20家可信合作伙伴开放有限预览,OpenAI计划在数周内推向更广泛市场。本文将从模型分层、核心能力、安全框架、政府审查、行业竞争五个维度深度解析GPT-5.6的技术内核与产业影响。
一、三层模型矩阵:从单一旗舰到天文命名体系
GPT-5.6不再是一个模型,而是一个产品家族。OpenAI此次放弃了沿用多代的数字迭代命名方式(如5.5→5.6),转而采用”数字+天体”的复合命名体系:数字标记代际,Sol(太阳)、Terra(大地)、Luna(月亮)分别对应旗舰、均衡、轻量三个能力层级。

这种命名背后是产品策略的根本性转变——三条产品线可以独立迭代,不再像过去那样”GPT-6替掉GPT-5″的简单更替。OpenAI在官方公告中明确表示,这种分层架构旨在让开发者根据任务复杂度与预算灵活选择,类似于手机产品线的”旗舰/标准/青春版”矩阵。
三款模型的核心定位与定价梯度如下:
- GPT-5.6 Sol(旗舰):面向最复杂的推理、科研、编程、网络安全和Agent任务,独有Ultra模式和Max reasoning effort深度推理能力。定价为每百万输入Token 5美元、每百万输出Token 30美元,与GPT-5.5同价。
- GPT-5.6 Terra(均衡):性能接近GPT-5.5但成本降低约50%,适用于日常办公、内容创作、企业级高频应用等通用场景。定价为每百万输入Token 2.5美元、每百万输出Token 15美元。
- GPT-5.6 Luna(轻量):主打极速响应与最低成本,适合高吞吐、大批量的简单文本处理场景。定价为每百万输入Token 1美元、每百万输出Token 6美元,是OpenAI目前最低价模型。
从定价梯度来看,OpenAI构建了一个3:1.5:1的能力-成本阶梯。Sol的价格是Luna的5倍,但性能差距在特定任务上可达10个百分点以上。这种分层策略的本质是用同一代架构覆盖从”极致推理”到”极致性价比”的完整需求光谱。
值得注意的是,Sol的定价仅为Anthropic Claude Fable 5(10美元/50美元)的一半左右,而Luna则与智谱GLM-5.2(1.4美元/4.4美元)处于同一价格带——OpenAI显然在用Luna守住低价市场,不让开源模型和中国厂商吃掉这块份额。
二、核心能力跃升:从聊天工具到数字特工
GPT-5.6的能力升级不再停留在单次问答的跑分上涨,而是聚焦于复杂、长链条、强依赖上下文的Agent工作流。OpenAI把这种能力称为”agentic capabilities”——让模型更像一个能独立执行任务的agent。
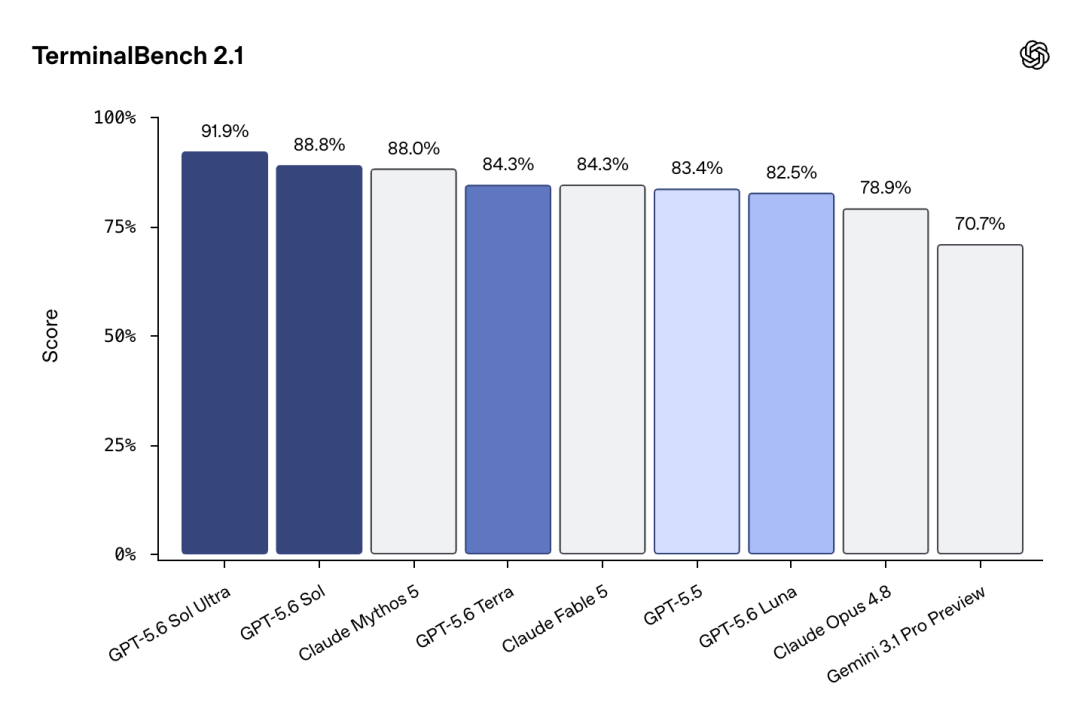
1. 编程能力:Terminal-Bench 2.1全面霸榜
在检验命令行工作流能力的Terminal-Bench 2.1基准测试中,GPT-5.6 Sol Ultra得分91.9%,Sol标准版88.8%,均超越GPT-5.5的88.0%和Anthropic Claude Mythos 5的84.3%/88.0%(不同来源数据略有差异)。横向对比其它模型:Claude Fable 5为83.4%,Claude Opus 4.8为78.9%,Google Gemini 3.1 Pro Preview仅70.7%。
这意味着Sol已超越GPT-5.5的编程上限,并首次在智能体编程任务中全面领先Mythos系列。更值得关注的是,GPT-5.6在无详细提示词的情况下能直接生成极简商用级UI(如”Lumen Notes”应用),告别旧版常见的”泥浆式”垃圾代码——早期泄露版本已能输出像素级精准的电商页面、动态布局、SVG等,彻底解决AI生成前端的”Slop”问题。
2. 上下文窗口与推理深度双升
GPT-5.6将上下文窗口从GPT-5.5的100万/105万tokens扩展至150万tokens,增幅约43%。实测可流畅处理90万tokens输入,并完美解决超105万tokens的请求。旧版通过Codex OAuth通道仅支持40万tokens,这一限制在GPT-5.6中被彻底打破。
推理分值(Juice Value)从GPT-5.5的768提升至960,增幅25%。新增的Max Reasoning模式允许Sol在复杂逻辑问题上分配更多计算资源,花更长时间进行深度推演,适合高复杂度任务;旧版GPT-5.5不具备该可调深度思考开关。
3. Ultra模式:多智能体协作的范式转折
Ultra模式是GPT-5.6最具突破性的设计——它不再由单个Agent完成任务,而是通过调用多个子智能体(subagents)并行协作,把复杂任务拆分处理,再统一汇总结果。这相当于让AI自己拆解任务、分配给一组AI协同完成。
在真实开发场景里,模型经常需要理解项目结构、读取文件、修改代码、运行命令、分析报错、继续修改。一个复杂任务通常无法靠一次回答完成。Ultra模式的方向是让多个子Agent分别处理不同环节,再把结果汇总起来,从而提高复杂任务的完成效率。旧版GPT-5.5仅支持单Agent串行,无法自主拆解任务。
4. 生物科研与网络安全专项突破
在GeneBench v1生物信息评测中,GPT-5.6 Sol用更少输出tokens取得了比GPT-5.5更强的结果,提升了科研场景成本效率。生物信息学、基因组学和定量生物分析经常需要模型持续分析数据、解释结果、选择方法、比较假设,并在多轮操作中保持上下文一致——如果Sol能在更少tokens下取得更强结果,意味着它在专业科研工作流中有更好的成本效率。
网络安全是GPT-5.6 Sol最敏感的能力方向。在ExploitBench测试中,Sol与Anthropic Mythos Preview表现相当,但仅使用了约三分之一的输出token,效率是旧版GPT-5.5的两倍以上。OpenAI将Sol定位为其迄今最强的网络安全模型,能够推进长周期安全任务的性能和效率边界,包括漏洞研究和exploitation相关任务。
不过OpenAI对这部分表述明显踩了刹车——官方强调Sol更擅长发现和修复漏洞,还不能稳定完成端到端攻击。在涉及Chromium和Firefox的评估中,Sol可以识别bug和程序缺陷(漏洞利用的基础组件),但在测试条件下没有自主生成可运行的完整攻击链。基于这些结果,OpenAI判断GPT-5.6 Sol尚未跨过Preparedness Framework中的网络安全关键风险阈值(Cyber Critical)。
三、分层安全栈:能力越强,防护越严
GPT-5.6的发布说明中,安全罕见地占据了较大篇幅。OpenAI为Sol、Terra、Luna配置了分级防护体系,能力越强,防护越严,目标是在压制攻击性用途的同时保留代码审查、漏洞研究、补丁开发、调试、安全教育、防御测试等合法场景。
这套分层安全栈涵盖多个环节:
- 模型层面:系统被训练为拒绝违规网络安全请求(包括越狱尝试),即便用户尝试伪装或绕过。
- 生成阶段:引入实时分类器,对高风险内容(网络安全和生物领域滥用)进行检测与拦截,必要时暂停生成并交由更大推理模型复核。
- 账号层面:结合跨对话行为与风险信号,识别持续性滥用vs合法双重用途工作。
- 差异化访问与执法机制:针对高风险情况设置多层拦截。
为了避免重蹈Anthropic Fable 5的覆辙(发布仅3天便被要求下线),OpenAI在自动化红队测试上投入了超过70万A100等效GPU小时,重点寻找通用jailbreak(越狱),并辅以专家人工测试。OpenAI还建立了快速响应流程,对新漏洞进行复现、评估与修复,并纳入持续评测体系。预览期间,用户可能会遇到拦截、拒答和延迟——OpenAI表示这种摩擦是有意为之,目的是在调整合法安全工作的误报率。
四、政府审查:从”自愿框架”到”一客一审”
GPT-5.6的发布方式比模型性能本身更受市场关注。OpenAI在公告中披露,在发布之前已向美国政府展示了计划及模型能力,”应政府要求”,将首先向一小部分”可信合作伙伴”提供有限预览,这些合作伙伴的参与情况已向政府报备。
据报道,首批获得权限的企业约20家左右,其中一个入口可能是亚马逊的Bedrock平台。更令人关注的是审批方式——部分客户的模型访问权限甚至需要美国政府逐一批准。OpenAI CEO山姆·奥特曼在内部备忘录中明确写道,在GPT-5.6的预览期内,客户将被逐一审批访问权限。这在AI发布史上尚属首次。
这一安排源于特朗普政府6月2日签署的AI行政令,该命令建立了针对前沿AI模型的安全评估框架,允许政府在模型发布前至多30天获取访问权限进行审查。虽然行政令强调参与”自愿”,但实际操作中已演变为事实上的强制审批。
OpenAI在公告中罕见加入了措辞强硬的声明:”我们不认为这种政府访问审批流程应成为长期默认做法。它剥夺了需要这些最佳工具的用户、开发者、企业、网络防御者和全球合作伙伴的使用权。”公司表示,目前的限量预览是”短期措施”,是未来几周实现更广泛开放的最有力路径,并计划与政府合作制定网络安全行政令框架,以及可重复执行的模型发布流程。
五、基础设施攻势:模型、安全、芯片三条线并进
把GPT-5.6放在OpenAI六月的完整动作序列里看,画面会更完整。6月12日,GPT-5.2从ChatGPT退役,所有用户被静默迁移到GPT-5.5;6月22日,Daybreak网络安全计划大规模扩展,GPT-5.5-Cyber全量版本上线;6月24日,和Broadcom联合发布第一颗自研推理芯片Jalapeño;然后就是6月26日——GPT-5.6三件套正式亮相。
两周之内退役旧模型、扩展安全平台、发布自研芯片、上线全新旗舰,四件事密集排列,这不是散点式的产品更新,而是一套完整的基础设施攻势。OpenAI正在从一家”做模型的公司”变成一家”控制AI全栈的公司”。
GPT-5.6还引入了更可预测的Prompt Caching机制:支持显式缓存断点,提供至少30分钟缓存生命周期。缓存写入按未缓存输入价格的1.25倍计费,读取则享受90%折扣。对于大量重复上下文的企业场景,这能进一步压低实际使用成本——尤其当Ultra模式会成倍增加子Agent调用时,可预测的缓存对Agent循环至关重要。
另外,OpenAI宣布7月将在Cerebras硬件上运行Sol,目标速度750 Token/秒,初期仅面向部分客户开放。如果这个数字属实,意味着用旗舰模型也能获得接近实时的响应体验——这是交互式Agent的生产级UX关键,独立于基准测试故事但与生产环境相关。
六、行业影响:大模型竞争进入新阶段
GPT-5.6相比前代的升级不再是简单的跑分上涨,而是三线并进:能力线(专业领域纵深)、成本线(分层定价+词元效率)、安全线(受控发布)。其核心变化在于:AI从”会聊天的助手”变成”能完成工作的数字员工”;从”单次问答”进化到”长链路自主执行”;从”单一模型”变成”小型AI团队”。
有分析师把GPT-5.6的发布意义总结为一句话:”整体模型时代结束了。”[^原文]以前CTO们的做法是把所有任务都塞给最贵的那个模型,现在得重新想清楚——哪个任务配用哪层。这件事听起来简单,做起来需要大量的工程评估、成本建模和路由决策。OpenAI把选择权给了用户,但也把复杂度一起打包过去了。
Ultra模式和子代理机制是真正面向未来的设计。当一个任务不再是一个模型一问一答,而是被拆分成多个并行子任务,模型本身的参数规模反而没那么重要了——Agent架构的成熟度和任务编排能力才是关键。这也是为什么OpenAI在Terminal-Bench这类测试”规划-迭代-工具协调”的基准上投入了大量精力。
对开发者而言,GPT-5.6目前还只是预览。等正式开放之后,那20家先拿到权限的公司怎么用、用在哪、选了Sol还是Terra,大概才是真正值得关注的下一阶段。GPT-5.6的”有限预览”并不只是产品灰度发布,更是一套安全验证流程——OpenAI需要在能力、风险与开放之间,找到一个可控的平衡点。
当模型能力逼近关键阈值,使用资格与使用方式,将成为比性能更为关注的事项。前沿AI模型正逐渐被纳入国家安全框架——过去新模型发布主要是公司产品节奏问题,现在一旦模型在编程、网络安全、生物和代理式工作流上跨过新的能力区间,发布节奏就可能被纳入安全和出口控制讨论。这种变化预示着前沿AI未来的魔幻走向。
文章来源: 综合OpenAI官方公告、explainx.ai、TechWeb、新浪科技、量子位、虎嗅、AI工具集、北京朝阳AI社区等多方资料整理改写。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...