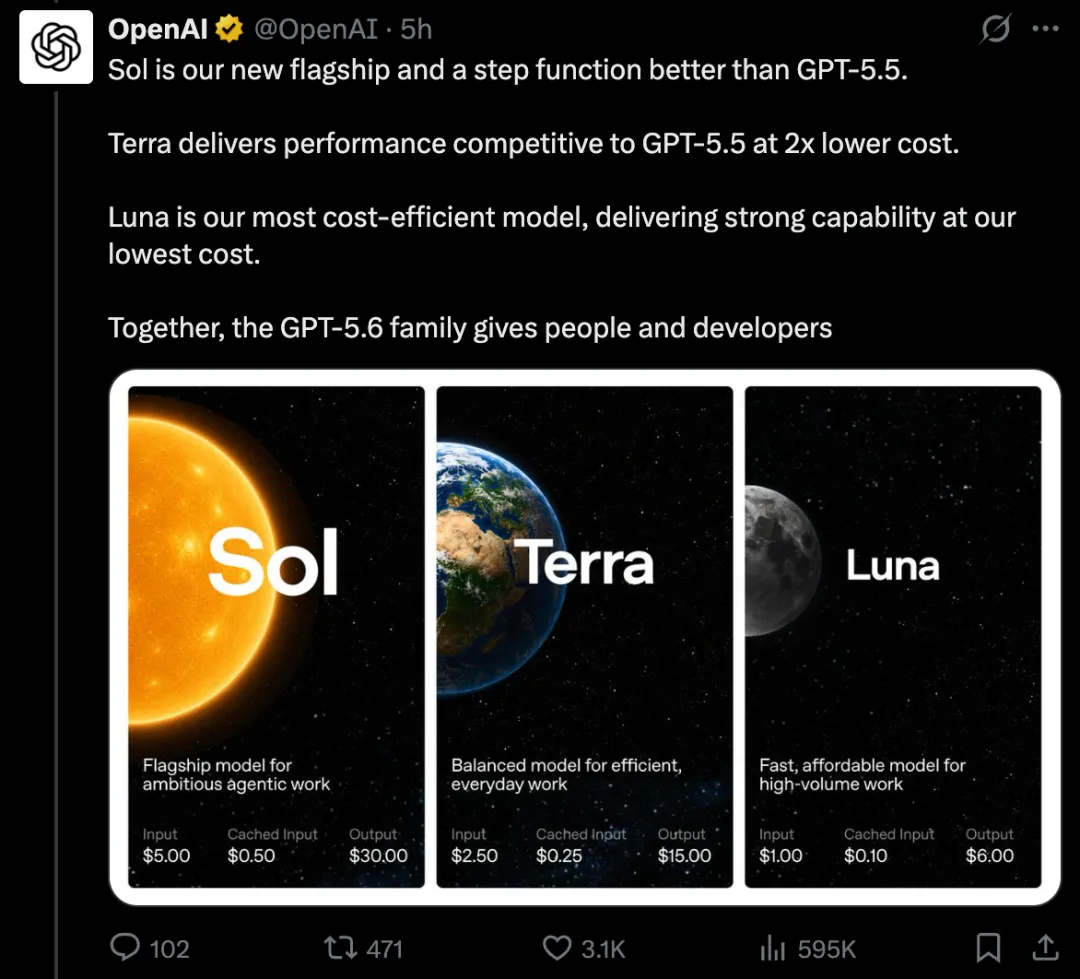
GPT-5.6重磅发布!OpenAI推出Sol/Terra/Luna全家桶,性能超越Claude Mythos 5 Ai资讯# AI大模型发布# Cerebras推理加速# Claude Mythos 5